 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning by Distilling Context
Paper and Code
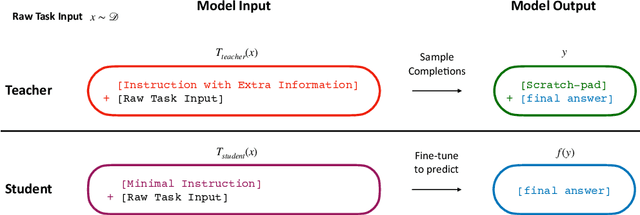

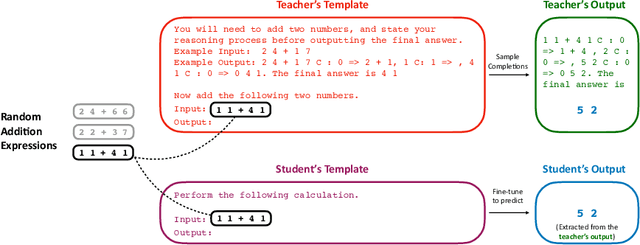

Language models significantly benefit from context tokens, such as prompts or scratchpads. They perform better when prompted with informative instructions, and they acquire new reasoning capabilities by generating a scratch-pad before predicting the final answers. However, they do not \textit{internalize} these performance gains, which disappear when the context tokens are gone. Our work proposes to apply context distillation so that a language model can improve itself by internalizing these gains. Concretely, given a synthetic unlabeled input for the target task, we condition the model on ``[instructions] + [task-input]'' to predict ``[scratch-pad] + [final answer]''; then we fine-tune the same model to predict its own ``[final answer]'' conditioned on the ``[task-input]'', without seeing the ``[instructions]'' or using the ``[scratch-pad]''. We show that context distillation is a general method to train language models, and it can effectively internalize 3 types of training signals. First, it can internalize abstract task instructions and explanations, so we can iteratively update the model parameters with new instructions and overwrite old ones. Second, it can internalize step-by-step reasoning for complex tasks (e.g., 8-digit addition), and such a newly acquired capability proves to be useful for other downstream tasks. Finally, it can internalize concrete training examples, and it outperforms directly learning with gradient descent by 9\% on the SPIDER Text-to-SQL dataset; furthermore, combining context distillation operations can internalize more training examples than the context window size allows.