 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Autonomous Exploration and Mapping with Semantic Vision
Paper and Code
Jan 15, 2019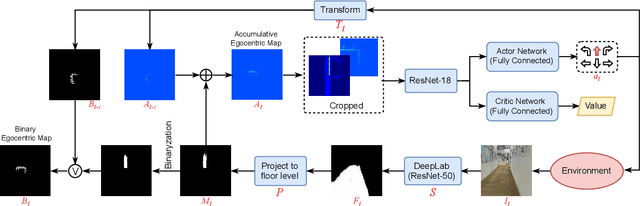
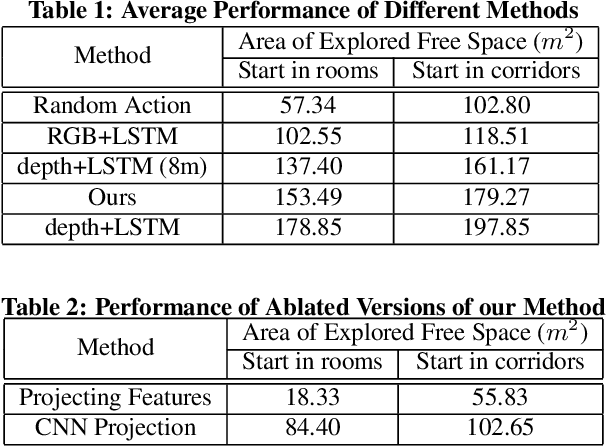
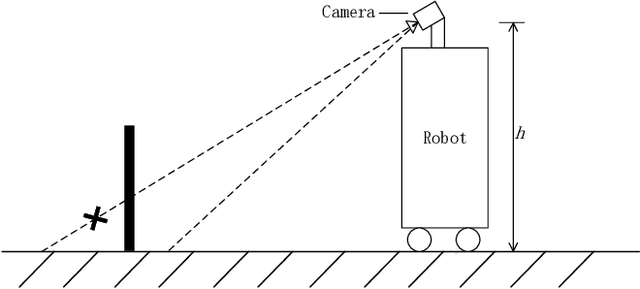
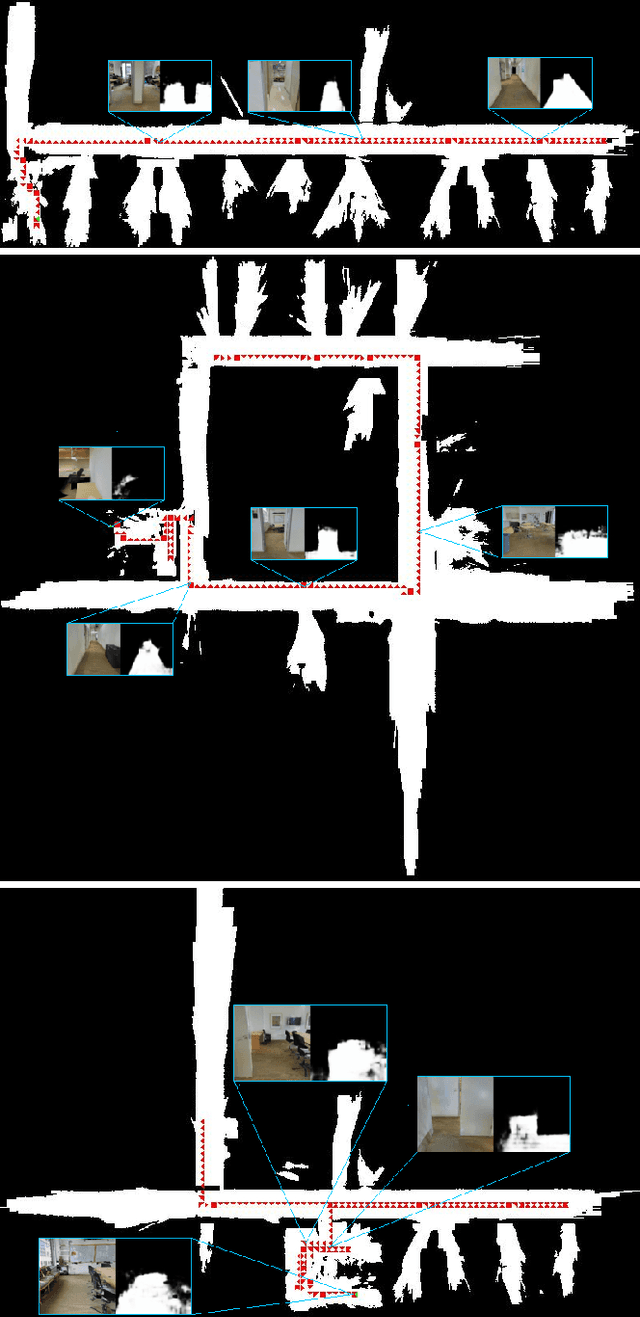
We address the problem of autonomous exploration and mapping for a mobile robot using visual inputs. Exploration and mapping is a well-known and key problem in robotics, the goal of which is to enable a robot to explore a new environment autonomously and create a map for future usage. Different to classical methods, we propose a learning-based approach this work based on semantic interpretation of visual scenes. Our method is based on a deep network consisting of three modules: semantic segmentation network, mapping using camera geometry and exploration action network. All modules are differentiable, so the whole pipeline is trained end-to-end based on actor-critic framework. Our network makes action decision step by step and generates the free space map simultaneously. To our best knowledge, this is the first algorithm that formulate exploration and mapping into learning framework. We validate our approach in simulated real world environments and demonstrate performance gains over competitive baseline approaches.