 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning an Invertible Output Mapping Can Mitigate Simplicity Bias in Neural Networks
Paper and Code

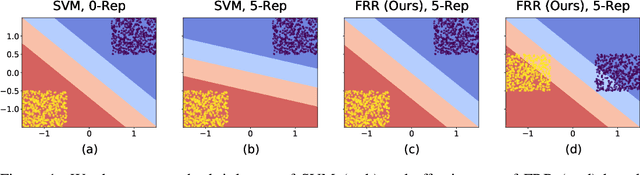
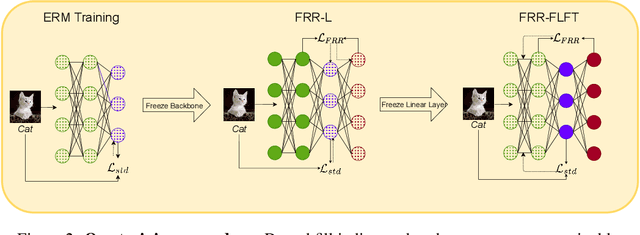
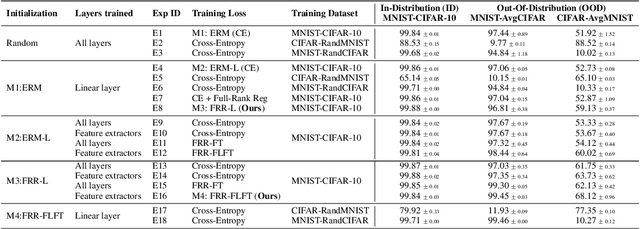
Deep Neural Networks are known to be brittle to even minor distribution shifts compared to the training distribution. While one line of work has demonstrated that Simplicity Bias (SB) of DNNs - bias towards learning only the simplest features - is a key reason for this brittleness, another recent line of work has surprisingly found that diverse/ complex features are indeed learned by the backbone, and their brittleness is due to the linear classification head relying primarily on the simplest features. To bridge the gap between these two lines of work, we first hypothesize and verify that while SB may not altogether preclude learning complex features, it amplifies simpler features over complex ones. Namely, simple features are replicated several times in the learned representations while complex features might not be replicated. This phenomenon, we term Feature Replication Hypothesis, coupled with the Implicit Bias of SGD to converge to maximum margin solutions in the feature space, leads the models to rely mostly on the simple features for classification. To mitigate this bias, we propose Feature Reconstruction Regularizer (FRR) to ensure that the learned features can be reconstructed back from the logits. The use of {\em FRR} in linear layer training (FRR-L) encourages the use of more diverse features for classification. We further propose to finetune the full network by freezing the weights of the linear layer trained using FRR-L, to refine the learned features, making them more suitable for classification. Using this simple solution, we demonstrate up to 15% gains in OOD accuracy on the recently introduced semi-synthetic datasets with extreme distribution shifts. Moreover, we demonstrate noteworthy gains over existing SOTA methods on the standard OOD benchmark DomainBed as well.