 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Adversarial Markov Decision Processes with Delayed Feedback
Paper and Code
Jan 29, 2021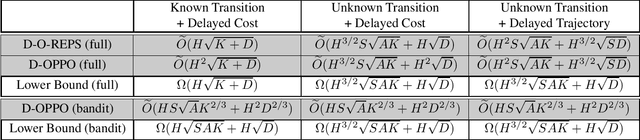
Reinforcement learning typically assumes that the agent observes feedback from the environment immediately, but in many real-world applications (like recommendation systems) the feedback is observed in delay. Thus, we consider online learning in episodic Markov decision processes (MDPs) with unknown transitions, adversarially changing costs and unrestricted delayed feedback. That is, the costs and trajectory of episode $k$ are only available at the end of episode $k + d^k$, where the delays $d^k$ are neither identical nor bounded, and are chosen by an adversary. We present novel algorithms based on policy optimization that achieve near-optimal high-probability regret of $\widetilde O ( \sqrt{K} + \sqrt{D} )$ under full-information feedback, where $K$ is the number of episodes and $D = \sum_{k} d^k$ is the total delay. Under bandit feedback, we prove similar $\widetilde O ( \sqrt{K} + \sqrt{D} )$ regret assuming that the costs are stochastic, and $\widetilde O ( K^{2/3} + D^{2/3} )$ regret in the general case. To our knowledge, we are the first to consider the important setting of delayed feedback in adversarial MDPs.