 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning A Unified Named Entity Tagger From Multiple Partially Annotated Corpora For Efficient Adaptation
Paper and Code

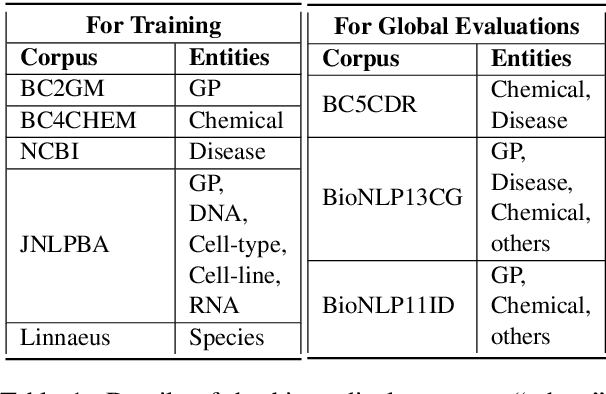
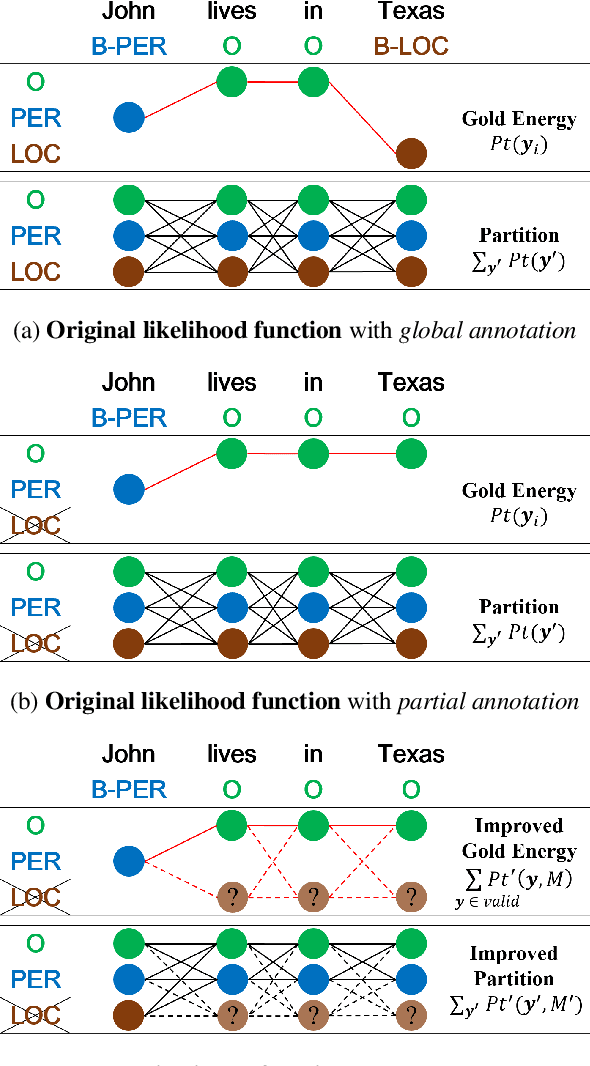
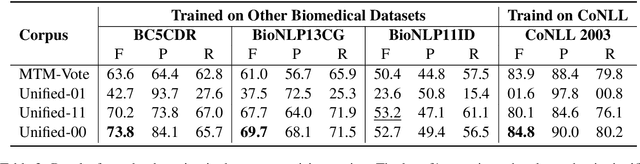
Named entity recognition (NER) identifies typed entity mentions in raw text. While the task is well-established, there is no universally used tagset: often, datasets are annotated for use in downstream applications and accordingly only cover a small set of entity types relevant to a particular task. For instance, in the biomedical domain, one corpus might annotate genes, another chemicals, and another diseases---despite the texts in each corpus containing references to all three types of entities. In this paper, we propose a deep structured model to integrate these "partially annotated" datasets to jointly identify all entity types appearing in the training corpora. By leveraging multiple datasets, the model can learn robust input representations; by building a joint structured model, it avoids potential conflicts caused by combining several models' predictions at test time. Experiments show that the proposed model significantly outperforms strong multi-task learning baselines when training on multiple, partially annotated datasets and testing on datasets that contain tags from more than one of the training corpora.