 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a hyperplane regressor by minimizing an exact bound on the VC dimension
Paper and Code
Oct 16, 2014
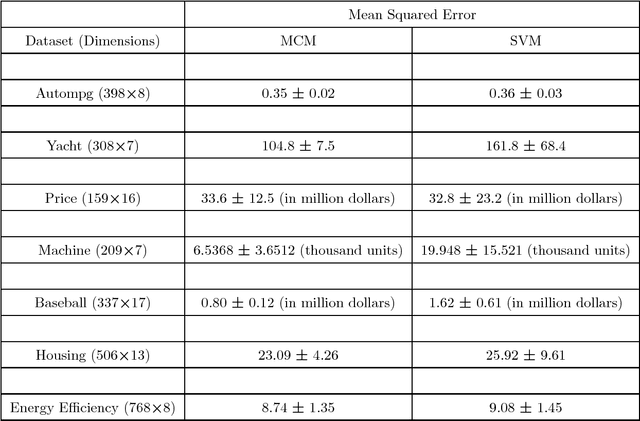
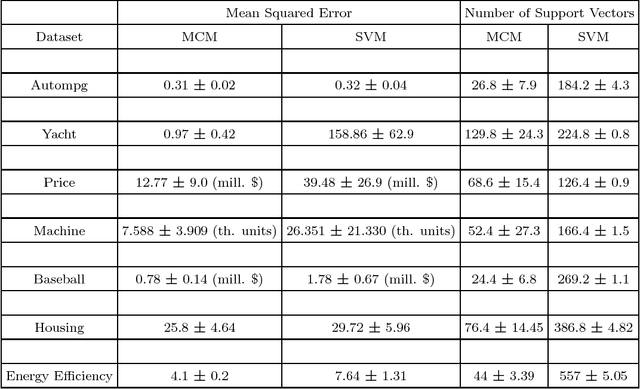
The capacity of a learning machine is measured by its Vapnik-Chervonenkis dimension, and learning machines with a low VC dimension generalize better. It is well known that the VC dimension of SVMs can be very large or unbounded, even though they generally yield state-of-the-art learning performance. In this paper, we show how to learn a hyperplane regressor by minimizing an exact, or \boldmath{$\Theta$} bound on its VC dimension. The proposed approach, termed as the Minimal Complexity Machine (MCM) Regressor, involves solving a simple linear programming problem. Experimental results show, that on a number of benchmark datasets, the proposed approach yields regressors with error rates much less than those obtained with conventional SVM regresssors, while often using fewer support vectors. On some benchmark datasets, the number of support vectors is less than one tenth the number used by SVMs, indicating that the MCM does indeed learn simpler representations.