 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-wise Shared Attention Network on Dynamical System Perspective
Paper and Code
Oct 27, 2022

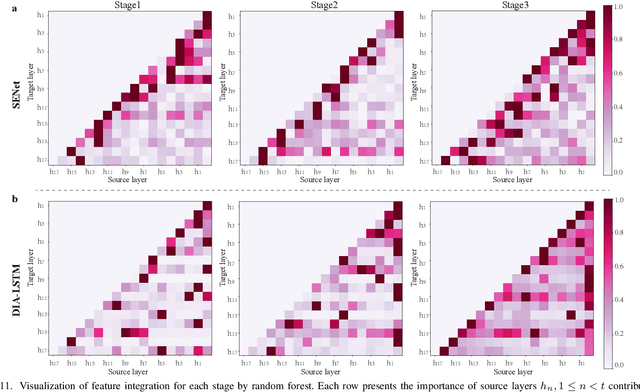

Attention networks have successfully boosted accuracy in various vision problems. Previous works lay emphasis on designing a new self-attention module and follow the traditional paradigm that individually plugs the modules into each layer of a network. However, such a paradigm inevitably increases the extra parameter cost with the growth of the number of layers. From the dynamical system perspective of the residual neural network, we find that the feature maps from the layers of the same stage are homogenous, which inspires us to propose a novel-and-simple framework, called the dense and implicit attention (DIA) unit, that shares a single attention module throughout different network layers. With our framework, the parameter cost is independent of the number of layers and we further improve the accuracy of existing popular self-attention modules with significant parameter reduction without any elaborated model crafting. Extensive experiments on benchmark datasets show that the DIA is capable of emphasizing layer-wise feature interrelation and thus leads to significant improvement in various vision tasks, including image classification, object detection, and medical application. Furthermore, the effectiveness of the DIA unit is demonstrated by novel experiments where we destabilize the model training by (1) removing the skip connection of the residual neural network, (2) removing the batch normalization of the model, and (3) removing all data augmentation during training. In these cases, we verify that DIA has a strong regularization ability to stabilize the training, i.e., the dense and implicit connections formed by our method can effectively recover and enhance the information communication across layers and the value of the gradient thus alleviate the training instability.