Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-wise Pruning and Auto-tuning of Layer-wise Learning Rates in Fine-tuning of Deep Networks
Paper and Code
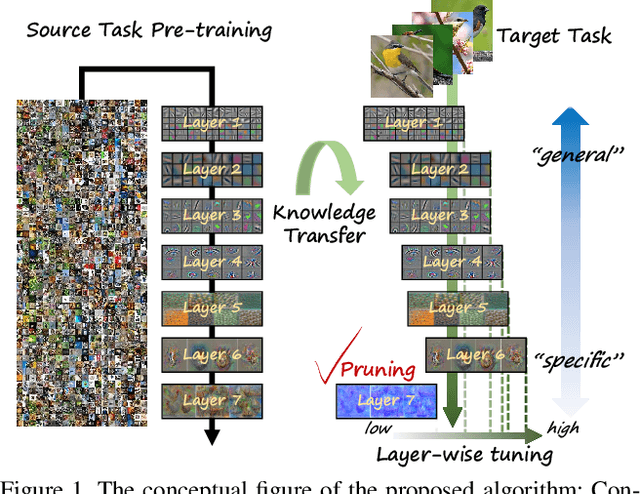
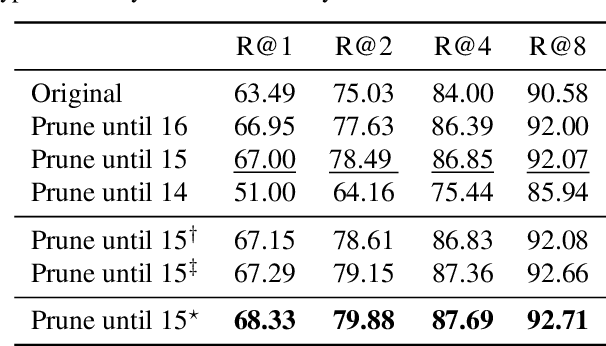
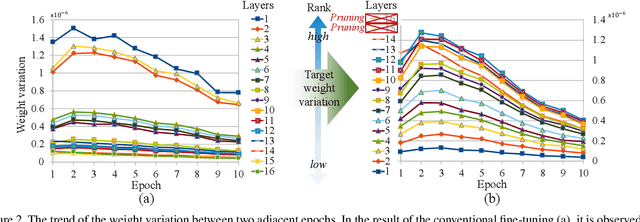

Existing fine-tuning methods use a single learning rate over all layers. In this paper, first, we discuss that trends of layer-wise weight variations by fine-tuning using a single learning rate do not match the well-known notion that lower-level layers extract general features and higher-level layers extract specific features. Based on our discussion, we propose an algorithm that improves fine-tuning performance and reduces network complexity through layer-wise pruning and auto-tuning of layer-wise learning rates. Through in-depth experiments on image retrieval (CUB-200-2011, Stanford online products, and Inshop) and fine-grained classification (Stanford cars, Aircraft) datasets, the effectiveness of the proposed algorithm is verified.
* 8 pages, 5 figures
View paper on