 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer Trajectory LSTM
Paper and Code
Aug 28, 2018
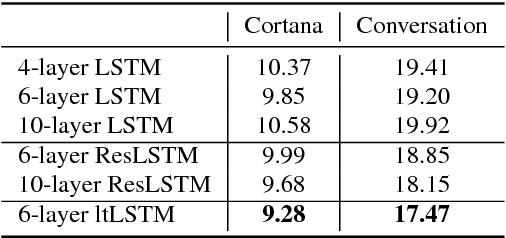
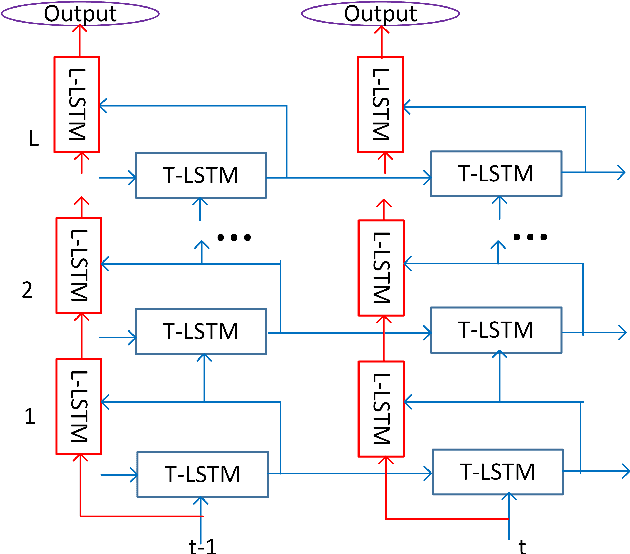
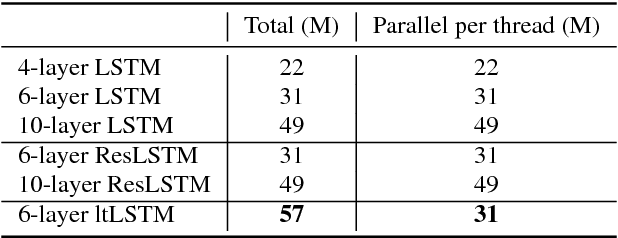
It is popular to stack LSTM layers to get better modeling power, especially when large amount of training data is available. However, an LSTM-RNN with too many vanilla LSTM layers is very hard to train and there still exists the gradient vanishing issue if the network goes too deep. This issue can be partially solved by adding skip connections between layers, such as residual LSTM. In this paper, we propose a layer trajectory LSTM (ltLSTM) which builds a layer-LSTM using all the layer outputs from a standard multi-layer time-LSTM. This layer-LSTM scans the outputs from time-LSTMs, and uses the summarized layer trajectory information for final senone classification. The forward-propagation of time-LSTM and layer-LSTM can be handled in two separate threads in parallel so that the network computation time is the same as the standard time-LSTM. With a layer-LSTM running through layers, a gated path is provided from the output layer to the bottom layer, alleviating the gradient vanishing issue. Trained with 30 thousand hours of EN-US Microsoft internal data, the proposed ltLSTM performed significantly better than the standard multi-layer LSTM and residual LSTM, with up to 9.0% relative word error rate reduction across different tasks.