 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLawin Transformer: Improving Semantic Segmentation Transformer with Multi-Scale Representations via Large Window Attention
Paper and Code
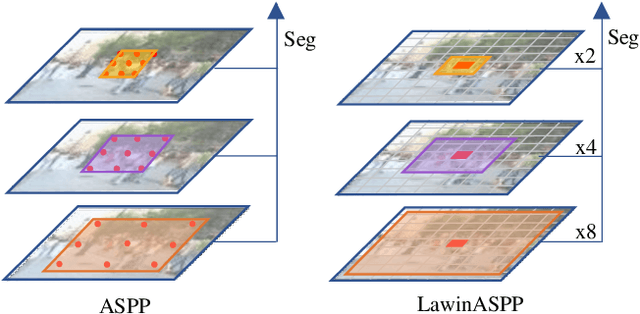
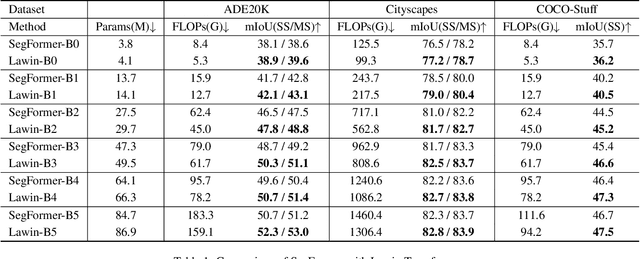
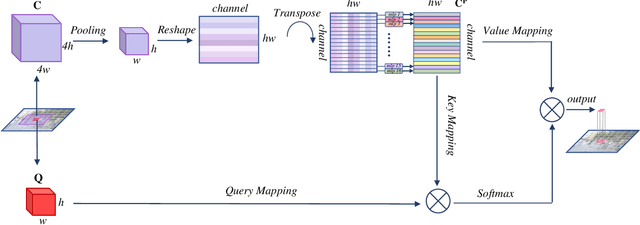
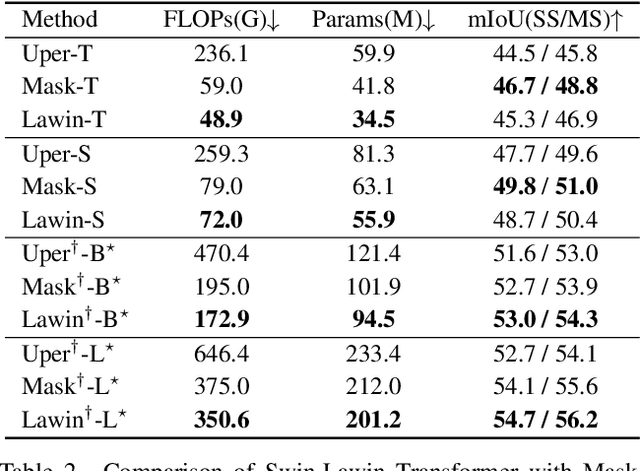
Multi-scale representations are crucial for semantic segmentation. The community has witnessed the flourish of semantic segmentation convolutional neural networks (CNN) exploiting multi-scale contextual information. Motivated by that the vision transformer (ViT) is powerful in image classification, some semantic segmentation ViTs are recently proposed, most of them attaining impressive results but at a cost of computational economy. In this paper, we succeed in introducing multi-scale representations into semantic segmentation ViT via window attention mechanism and further improves the performance and efficiency. To this end, we introduce large window attention which allows the local window to query a larger area of context window at only a little computation overhead. By regulating the ratio of the context area to the query area, we enable the large window attention to capture the contextual information at multiple scales. Moreover, the framework of spatial pyramid pooling is adopted to collaborate with the large window attention, which presents a novel decoder named large window attention spatial pyramid pooling (LawinASPP) for semantic segmentation ViT. Our resulting ViT, Lawin Transformer, is composed of an efficient hierachical vision transformer (HVT) as encoder and a LawinASPP as decoder. The empirical results demonstrate that Lawin Transformer offers an improved efficiency compared to the existing method. Lawin Transformer further sets new state-of-the-art performance on Cityscapes (84.4\% mIoU), ADE20K (56.2\% mIoU) and COCO-Stuff datasets. The code will be released at https://github.com/yan-hao-tian/lawin.