 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLattice-Based Methods Surpass Sum-of-Squares in Clustering
Paper and Code
Jan 07, 2022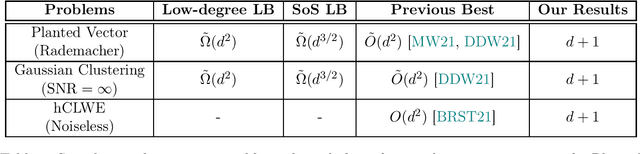
Clustering is a fundamental primitive in unsupervised learning which gives rise to a rich class of computationally-challenging inference tasks. In this work, we focus on the canonical task of clustering d-dimensional Gaussian mixtures with unknown (and possibly degenerate) covariance. Recent works (Ghosh et al. '20; Mao, Wein '21; Davis, Diaz, Wang '21) have established lower bounds against the class of low-degree polynomial methods and the sum-of-squares (SoS) hierarchy for recovering certain hidden structures planted in Gaussian clustering instances. Prior work on many similar inference tasks portends that such lower bounds strongly suggest the presence of an inherent statistical-to-computational gap for clustering, that is, a parameter regime where the clustering task is statistically possible but no polynomial-time algorithm succeeds. One special case of the clustering task we consider is equivalent to the problem of finding a planted hypercube vector in an otherwise random subspace. We show that, perhaps surprisingly, this particular clustering model does not exhibit a statistical-to-computational gap, even though the aforementioned low-degree and SoS lower bounds continue to apply in this case. To achieve this, we give a polynomial-time algorithm based on the Lenstra--Lenstra--Lovasz lattice basis reduction method which achieves the statistically-optimal sample complexity of d+1 samples. This result extends the class of problems whose conjectured statistical-to-computational gaps can be "closed" by "brittle" polynomial-time algorithms, highlighting the crucial but subtle role of noise in the onset of statistical-to-computational gaps.