Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLate Temporal Modeling in 3D CNN Architectures with BERT for Action Recognition
Paper and Code
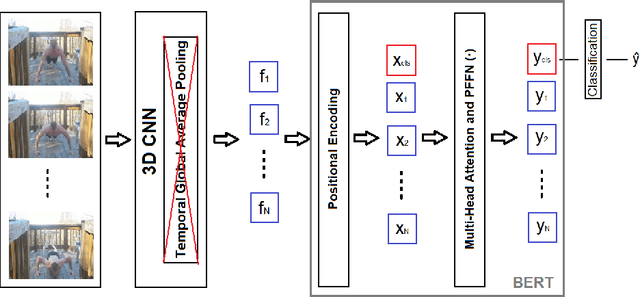



In this work, we combine 3D convolution with late temporal modeling for action recognition. For this aim, we replace the conventional Temporal Global Average Pooling (TGAP) layer at the end of 3D convolutional architecture with the Bidirectional Encoder Representations from Transformers (BERT) layer in order to better utilize the temporal information with BERT's attention mechanism. We show that this replacement improves the performances of many popular 3D convolution architectures for action recognition, including ResNeXt, I3D, SlowFast and R(2+1)D. Moreover, we provide the-state-of-the-art results on both HMDB51 and UCF101 datasets with 85.10% and 98.69% top-1 accuracy, respectively. The code is publicly available.
View paper on