 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Need Consultants for Reasoning: Becoming an Expert in a Complex Human System Through Behavior Simulation
Paper and Code
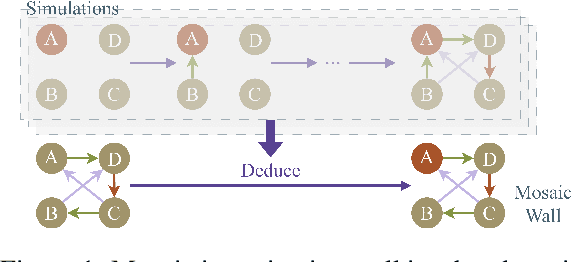
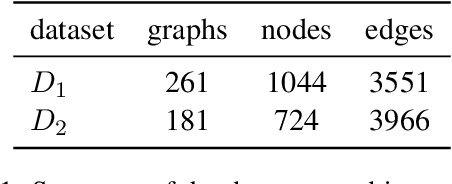
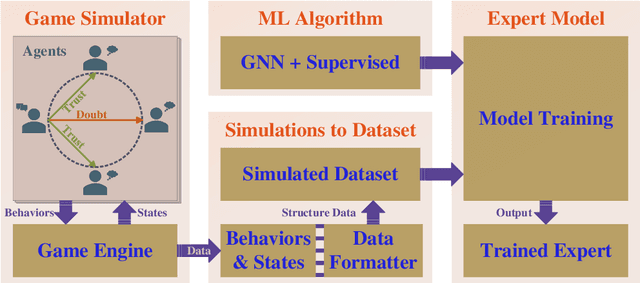
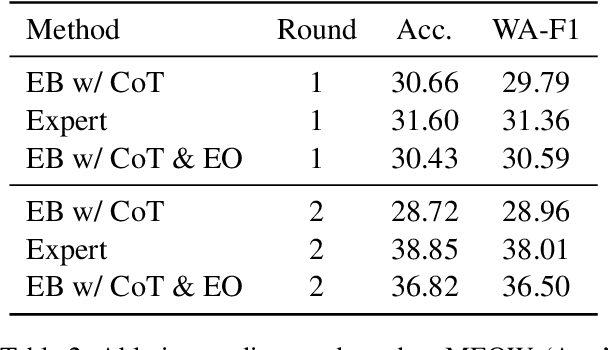
Large language models (LLMs), in conjunction with various reasoning reinforcement methodologies, have demonstrated remarkable capabilities comparable to humans in fields such as mathematics, law, coding, common sense, and world knowledge. In this paper, we delve into the reasoning abilities of LLMs within complex human systems. We propose a novel reasoning framework, termed ``Mosaic Expert Observation Wall'' (MEOW) exploiting generative-agents-based simulation technique. In the MEOW framework, simulated data are utilized to train an expert model concentrating ``experience'' about a specific task in each independent time of simulation. It is the accumulated ``experience'' through the simulation that makes for an expert on a task in a complex human system. We conduct the experiments within a communication game that mirrors real-world security scenarios. The results indicate that our proposed methodology can cooperate with existing methodologies to enhance the reasoning abilities of LLMs in complex human systems.