 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Context Conversational Representation Learning: Self-Supervised Learning for Conversational Documents
Paper and Code
Feb 16, 2021

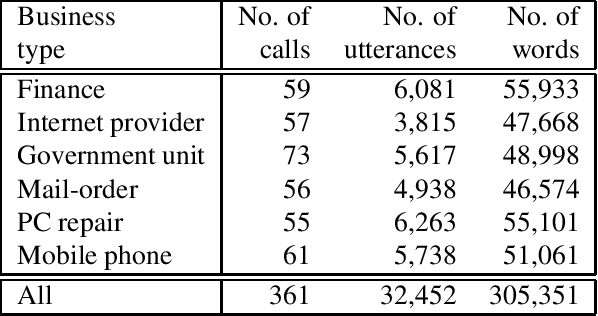

This paper presents a novel self-supervised learning method for handling conversational documents consisting of transcribed text of human-to-human conversations. One of the key technologies for understanding conversational documents is utterance-level sequential labeling, where labels are estimated from the documents in an utterance-by-utterance manner. The main issue with utterance-level sequential labeling is the difficulty of collecting labeled conversational documents, as manual annotations are very costly. To deal with this issue, we propose large-context conversational representation learning (LC-CRL), a self-supervised learning method specialized for conversational documents. A self-supervised learning task in LC-CRL involves the estimation of an utterance using all the surrounding utterances based on large-context language modeling. In this way, LC-CRL enables us to effectively utilize unlabeled conversational documents and thereby enhances the utterance-level sequential labeling. The results of experiments on scene segmentation tasks using contact center conversational datasets demonstrate the effectiveness of the proposed method.