 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLANIT: Language-Driven Image-to-Image Translation for Unlabeled Data
Paper and Code

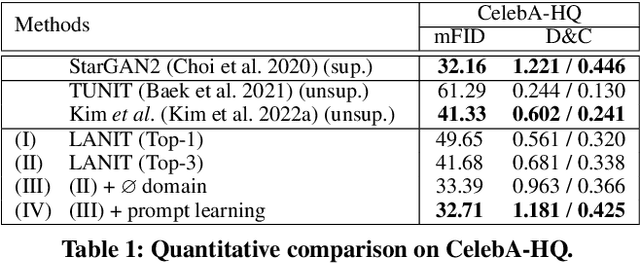
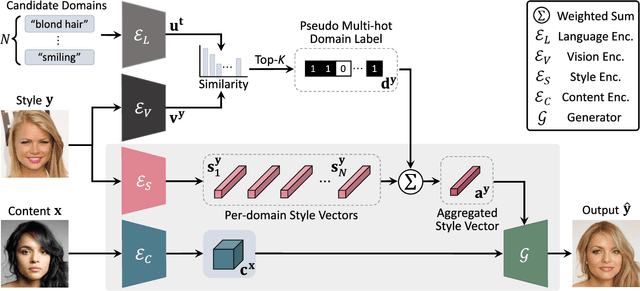
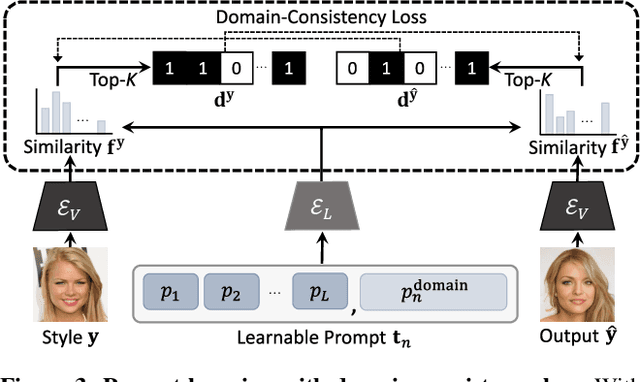
Existing techniques for image-to-image translation commonly have suffered from two critical problems: heavy reliance on per-sample domain annotation and/or inability of handling multiple attributes per image. Recent methods adopt clustering approaches to easily provide per-sample annotations in an unsupervised manner. However, they cannot account for the real-world setting; one sample may have multiple attributes. In addition, the semantics of the clusters are not easily coupled to human understanding. To overcome these, we present a LANguage-driven Image-to-image Translation model, dubbed LANIT. We leverage easy-to-obtain candidate domain annotations given in texts for a dataset and jointly optimize them during training. The target style is specified by aggregating multi-domain style vectors according to the multi-hot domain assignments. As the initial candidate domain texts might be inaccurate, we set the candidate domain texts to be learnable and jointly fine-tune them during training. Furthermore, we introduce a slack domain to cover samples that are not covered by the candidate domains. Experiments on several standard benchmarks demonstrate that LANIT achieves comparable or superior performance to the existing model.