 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Largely Exhibit Human-like Constituent Ordering Preferences
Paper and Code
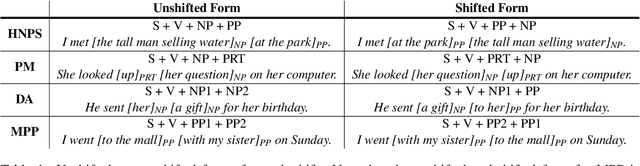

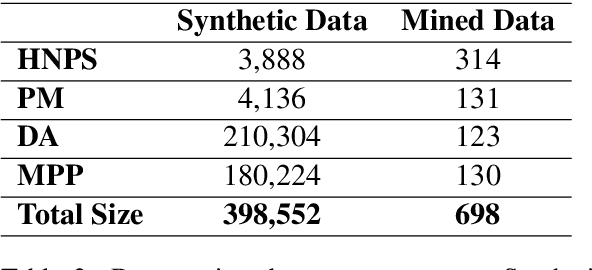

Though English sentences are typically inflexible vis-\`a-vis word order, constituents often show far more variability in ordering. One prominent theory presents the notion that constituent ordering is directly correlated with constituent weight: a measure of the constituent's length or complexity. Such theories are interesting in the context of natural language processing (NLP), because while recent advances in NLP have led to significant gains in the performance of large language models (LLMs), much remains unclear about how these models process language, and how this compares to human language processing. In particular, the question remains whether LLMs display the same patterns with constituent movement, and may provide insights into existing theories on when and how the shift occurs in human language. We compare a variety of LLMs with diverse properties to evaluate broad LLM performance on four types of constituent movement: heavy NP shift, particle movement, dative alternation, and multiple PPs. Despite performing unexpectedly around particle movement, LLMs generally align with human preferences around constituent ordering.