 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Model-Driven Unsupervised Neural Machine Translation
Paper and Code
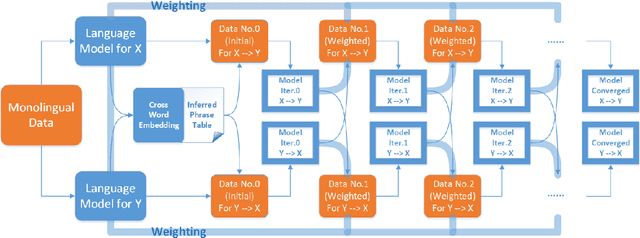
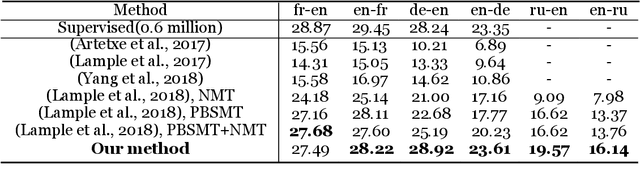
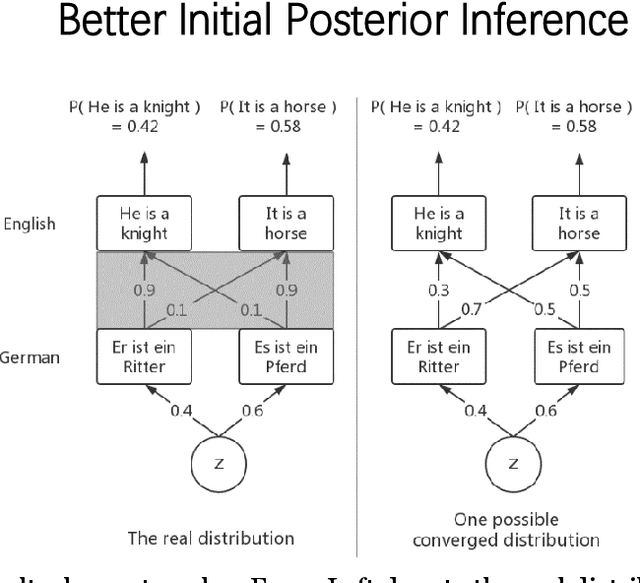
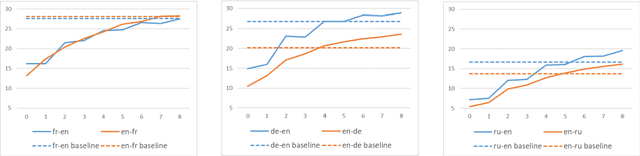
Unsupervised neural machine translation(NMT) is associated with noise and errors in synthetic data when executing vanilla back-translations. Here, we explicitly exploits language model(LM) to drive construction of an unsupervised NMT system. This features two steps. First, we initialize NMT models using synthetic data generated via temporary statistical machine translation(SMT). Second, unlike vanilla back-translation, we formulate a weight function, that scores synthetic data at each step of subsequent iterative training; this allows unsupervised training to an improved outcome. We present the detailed mathematical construction of our method. Experimental WMT2014 English-French, and WMT2016 English-German and English-Russian translation tasks revealed that our method outperforms the best prior systems by more than 3 BLEU points.