 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangevin Dynamics for Inverse Reinforcement Learning of Stochastic Gradient Algorithms
Paper and Code
Jun 20, 2020

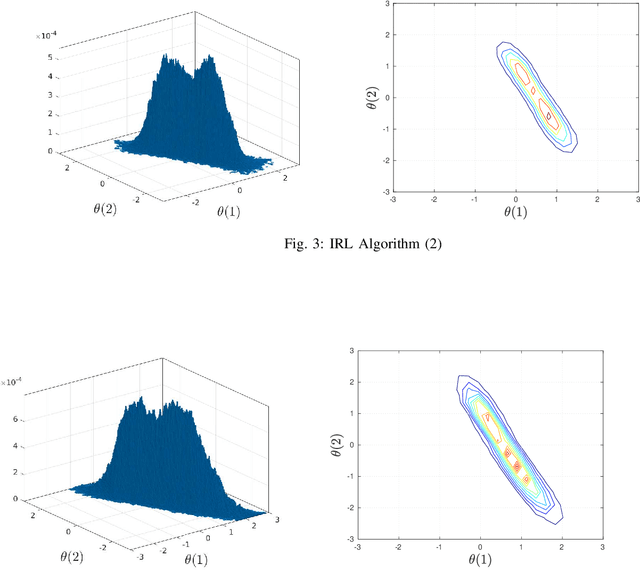
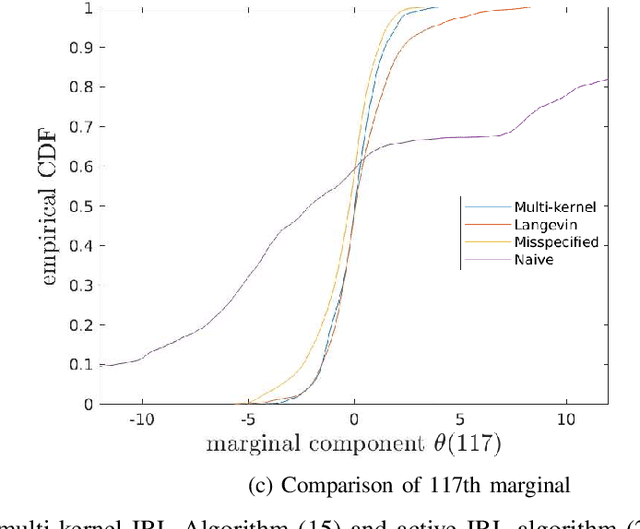
Inverse reinforcement learning (IRL) aims to estimate the reward function of optimizing agents by observing their response (estimates or actions). This paper considers IRL when noisy estimates of the gradient of a reward function generated by multiple stochastic gradient agents are observed. We present a generalized Langevin dynamics algorithm to estimate the reward function $R(\theta)$; specifically, the resulting Langevin algorithm asymptotically generates samples from the distribution proportional to $\exp(R(\theta))$. The proposed IRL algorithms use kernel-based passive learning schemes. We also construct multi-kernel passive Langevin algorithms for IRL which are suitable for high dimensional data. The performance of the proposed IRL algorithms are illustrated on examples in adaptive Bayesian learning, logistic regression (high dimensional problem) and constrained Markov decision processes. We prove weak convergence of the proposed IRL algorithms using martingale averaging methods. We also analyze the tracking performance of the IRL algorithms in non-stationary environments where the utility function $R(\theta)$ jump changes over time as a slow Markov chain.