 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangevin DQN
Paper and Code
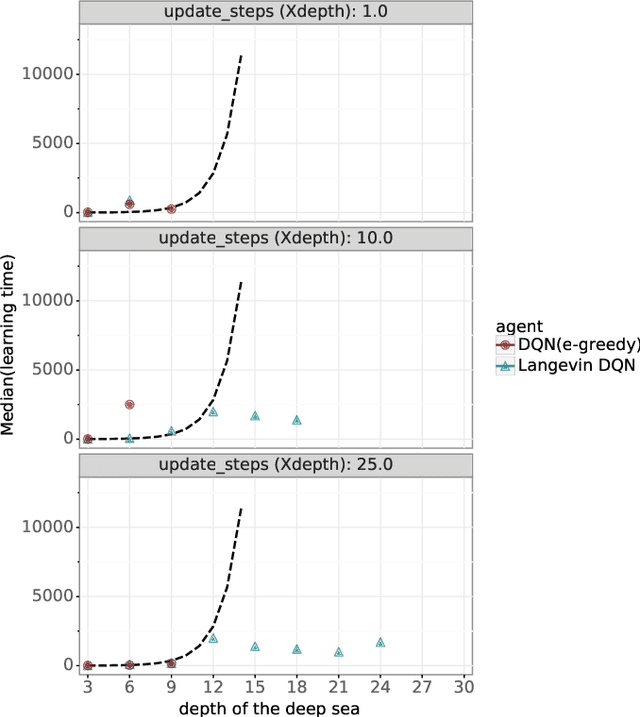
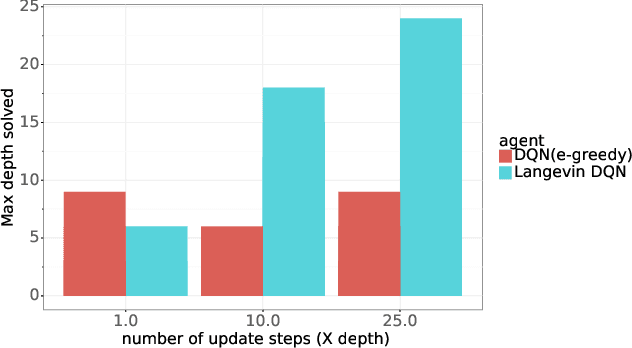
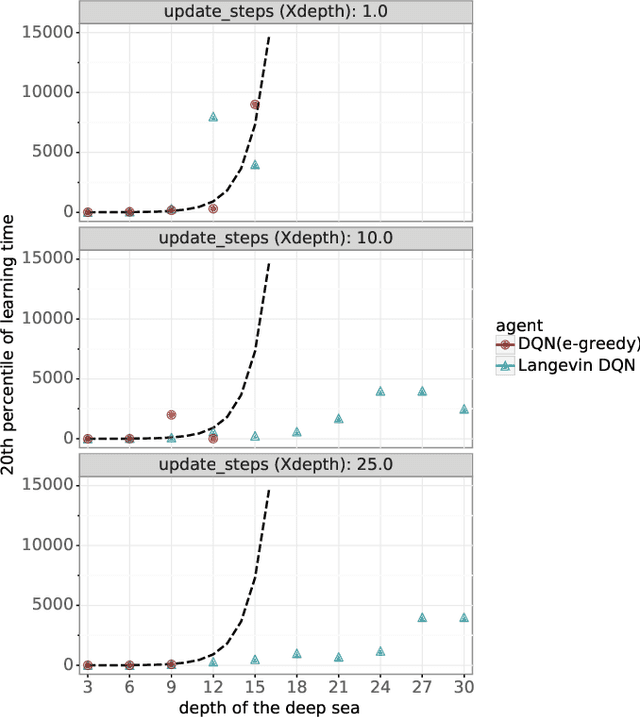
Algorithms that tackle deep exploration -- an important challenge in reinforcement learning -- have relied on epistemic uncertainty representation through ensembles or other hypermodels, exploration bonuses, or visitation count distributions. An open question is whether deep exploration can be achieved by an incremental reinforcement learning algorithm that tracks a single point estimate, without additional complexity required to account for epistemic uncertainty. We answer this question in the affirmative. In particular, we develop Langevin DQN, a variation of DQN that differs only in perturbing parameter updates with Gaussian noise, and demonstrate through a computational study that the algorithm achieves deep exploration. We also provide an intuition for why Langevin DQN performs deep exploration.