 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLack of Fluency is Hurting Your Translation Model
Paper and Code

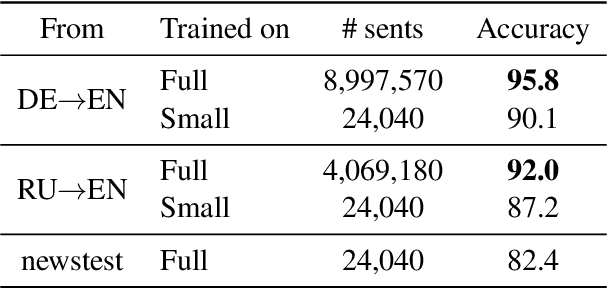
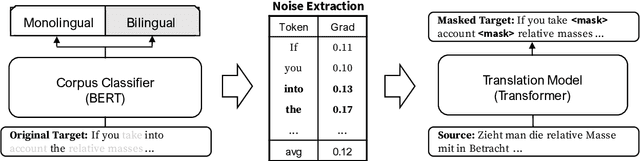
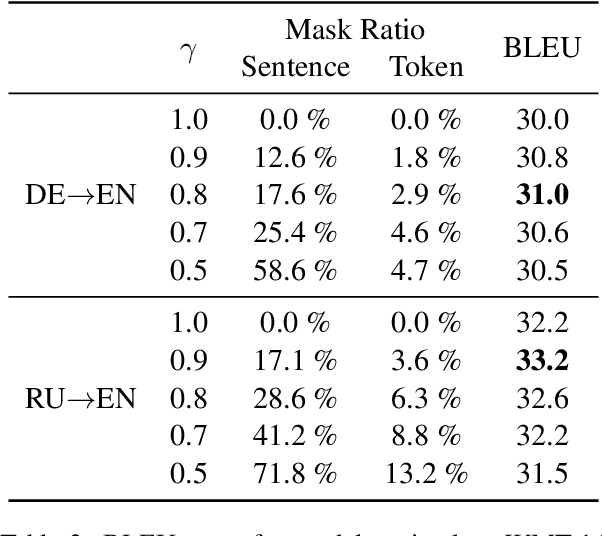
Many machine translation models are trained on bilingual corpus, which consist of aligned sentence pairs from two different languages with same semantic. However, there is a qualitative discrepancy between train and test set in bilingual corpus. While the most train sentences are created via automatic techniques such as crawling and sentence-alignment methods, the test sentences are annotated with the consideration of fluency by human. We suppose this discrepancy in training corpus will yield performance drop of translation model. In this work, we define \textit{fluency noise} to determine which parts of train sentences cause them to seem unnatural. We show that \textit{fluency noise} can be detected by simple gradient-based method with pre-trained classifier. By removing \textit{fluency noise} in train sentences, our final model outperforms the baseline on WMT-14 DE$\rightarrow$EN and RU$\rightarrow$EN. We also show the compatibility with back-translation augmentation, which has been commonly used to improve the fluency of the translation model. At last, the qualitative analysis of \textit{fluency noise} provides the insight of what points we should focus on.