Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Calibration for Semantic Segmentation Under Domain Shift
Paper and Code
Jul 20, 2023

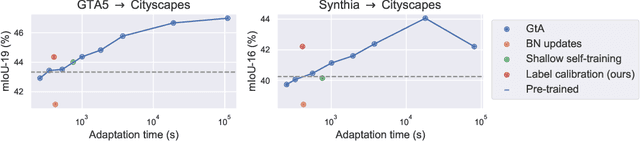

Performance of a pre-trained semantic segmentation model is likely to substantially decrease on data from a new domain. We show a pre-trained model can be adapted to unlabelled target domain data by calculating soft-label prototypes under the domain shift and making predictions according to the prototype closest to the vector with predicted class probabilities. The proposed adaptation procedure is fast, comes almost for free in terms of computational resources and leads to considerable performance improvements. We demonstrate the benefits of such label calibration on the highly-practical synthetic-to-real semantic segmentation problem.
* ICLR 2023 Workshop on Pitfalls of Limited Data and Computation for
Trustworthy ML
View paper on
 OpenReview
OpenReview