 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Augmented Dataset Distillation
Paper and Code
Sep 24, 2024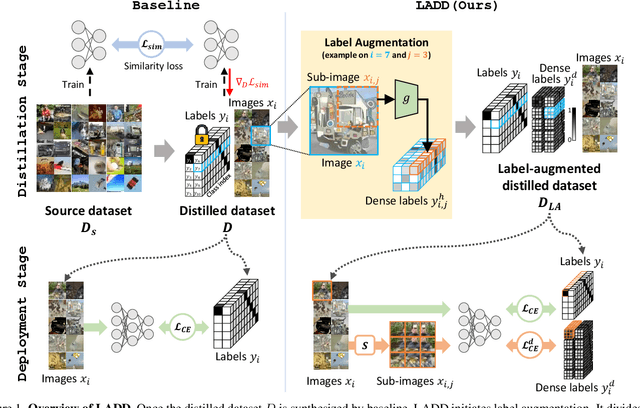
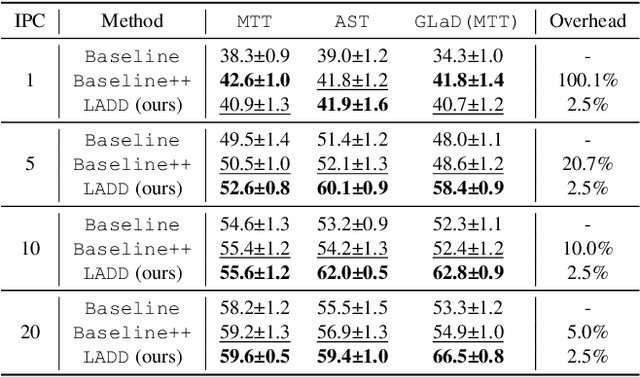
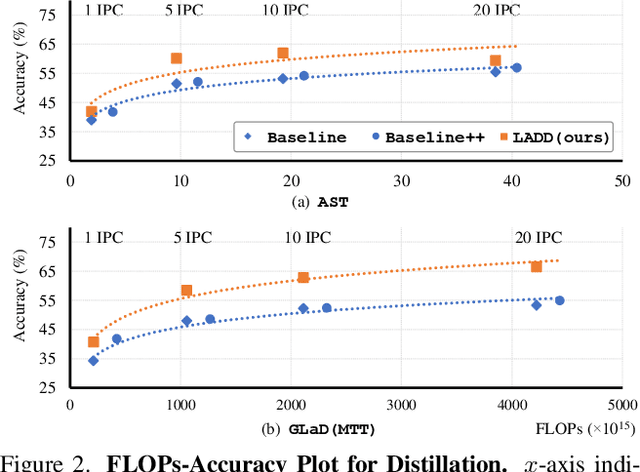
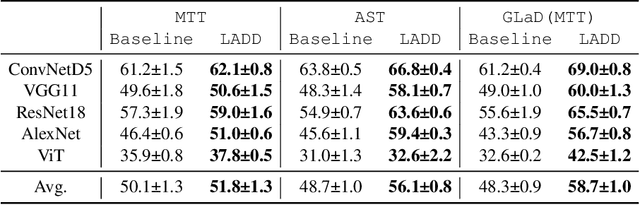
Traditional dataset distillation primarily focuses on image representation while often overlooking the important role of labels. In this study, we introduce Label-Augmented Dataset Distillation (LADD), a new dataset distillation framework enhancing dataset distillation with label augmentations. LADD sub-samples each synthetic image, generating additional dense labels to capture rich semantics. These dense labels require only a 2.5% increase in storage (ImageNet subsets) with significant performance benefits, providing strong learning signals. Our label generation strategy can complement existing dataset distillation methods for significantly enhancing their training efficiency and performance. Experimental results demonstrate that LADD outperforms existing methods in terms of computational overhead and accuracy. With three high-performance dataset distillation algorithms, LADD achieves remarkable gains by an average of 14.9% in accuracy. Furthermore, the effectiveness of our method is proven across various datasets, distillation hyperparameters, and algorithms. Finally, our method improves the cross-architecture robustness of the distilled dataset, which is important in the application scenario.