Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL4: Practical loss-based stepsize adaptation for deep learning
Paper and Code

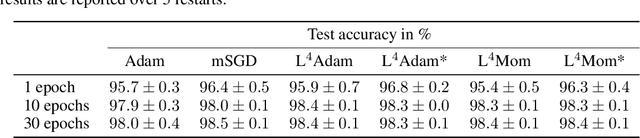

We propose a stepsize adaptation scheme for stochastic gradient descent. It operates directly with the loss function and rescales the gradient in order to make fixed predicted progress on the loss. We demonstrate its capabilities by conclusively improving the performance of Adam and Momentum optimizers. The enhanced optimizers with default hyperparameters consistently outperform their constant stepsize counterparts, even the best ones, without a measurable increase in computational cost. The performance is validated on multiple architectures including dense nets, CNNs, ResNets, and the recurrent Differential Neural Computer on classical datasets MNIST, fashion MNIST, CIFAR10 and others.
View paper on