 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL3CubeMahaSent: A Marathi Tweet-based Sentiment Analysis Dataset
Paper and Code

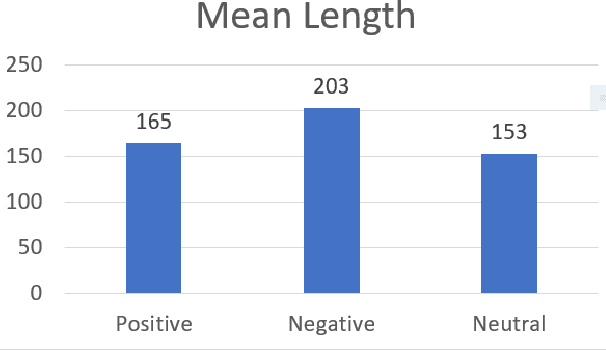

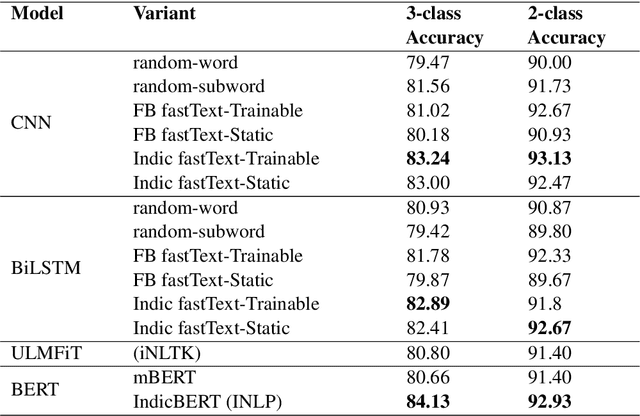
Sentiment analysis is one of the most fundamental tasks in Natural Language Processing. Popular languages like English, Arabic, Russian, Mandarin, and also Indian languages such as Hindi, Bengali, Tamil have seen a significant amount of work in this area. However, the Marathi language which is the third most popular language in India still lags behind due to the absence of proper datasets. In this paper, we present the first major publicly available Marathi Sentiment Analysis Dataset - L3CubeMahaSent. It is curated using tweets extracted from various Maharashtrian personalities' Twitter accounts. Our dataset consists of ~16,000 distinct tweets classified in three broad classes viz. positive, negative, and neutral. We also present the guidelines using which we annotated the tweets. Finally, we present the statistics of our dataset and baseline classification results using CNN, LSTM, ULMFiT, and BERT-based deep learning models.