 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL3-Net Deep Audio Embeddings to Improve COVID-19 Detection from Smartphone Data
Paper and Code


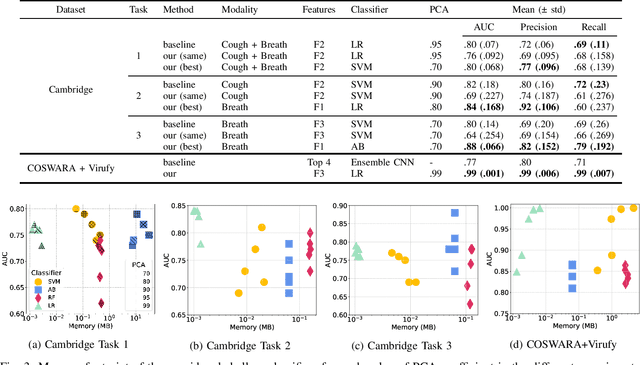

Smartphones and wearable devices, along with Artificial Intelligence, can represent a game-changer in the pandemic control, by implementing low-cost and pervasive solutions to recognize the development of new diseases at their early stages and by potentially avoiding the rise of new outbreaks. Some recent works show promise in detecting diagnostic signals of COVID-19 from voice and coughs by using machine learning and hand-crafted acoustic features. In this paper, we decided to investigate the capabilities of the recently proposed deep embedding model L3-Net to automatically extract meaningful features from raw respiratory audio recordings in order to improve the performances of standard machine learning classifiers in discriminating between COVID-19 positive and negative subjects from smartphone data. We evaluated the proposed model on 3 datasets, comparing the obtained results with those of two reference works. Results show that the combination of L3-Net with hand-crafted features overcomes the performance of the other works of 28.57% in terms of AUC in a set of subject-independent experiments. This result paves the way to further investigation on different deep audio embeddings, also for the automatic detection of different diseases.