 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Transfer and Distillation from Autoregressive to Non-Autoregressive Speech Recognition
Paper and Code
Jul 15, 2022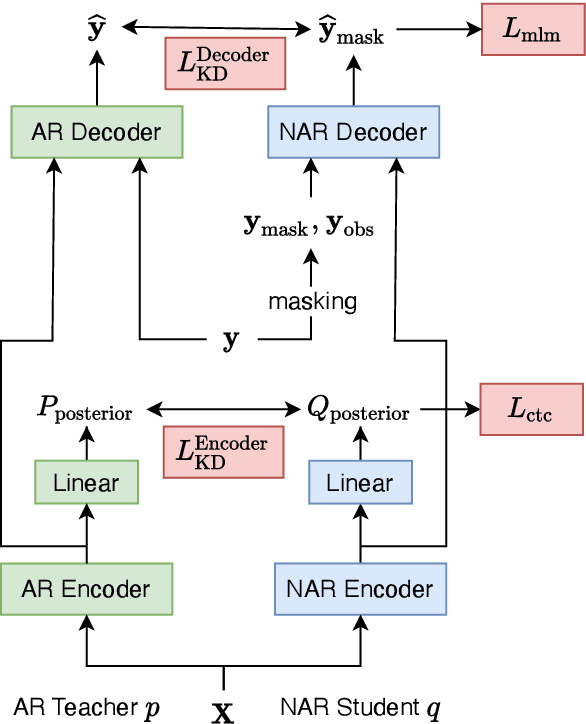



Modern non-autoregressive~(NAR) speech recognition systems aim to accelerate the inference speed; however, they suffer from performance degradation compared with autoregressive~(AR) models as well as the huge model size issue. We propose a novel knowledge transfer and distillation architecture that leverages knowledge from AR models to improve the NAR performance while reducing the model's size. Frame- and sequence-level objectives are well-designed for transfer learning. To further boost the performance of NAR, a beam search method on Mask-CTC is developed to enlarge the search space during the inference stage. Experiments show that the proposed NAR beam search relatively reduces CER by over 5% on AISHELL-1 benchmark with a tolerable real-time-factor~(RTF) increment. By knowledge transfer, the NAR student who has the same size as the AR teacher obtains relative CER reductions of 8/16% on AISHELL-1 dev/test sets, and over 25% relative WER reductions on LibriSpeech test-clean/other sets. Moreover, the ~9x smaller NAR models achieve ~25% relative CER/WER reductions on both AISHELL-1 and LibriSpeech benchmarks with the proposed knowledge transfer and distillation.