 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge accumulating: The general pattern of learning
Paper and Code
Aug 09, 2021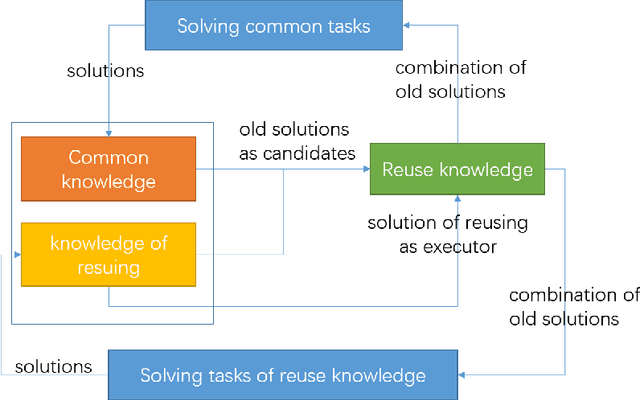
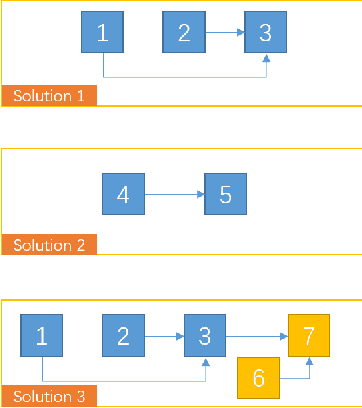
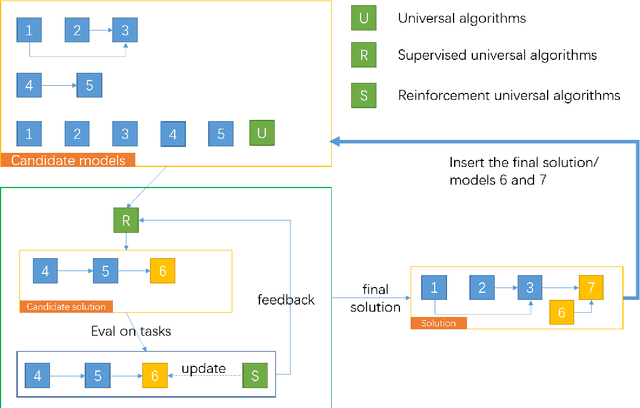
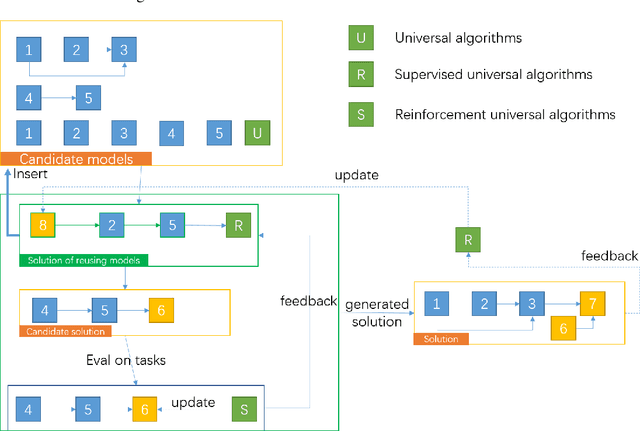
Artificial Intelligence has been developed for decades with the achievement of great progress. Recently, deep learning shows its ability to solve many real world problems, e.g. image classification and detection, natural language processing, playing GO. Theoretically speaking, an artificial neural network can fit any function and reinforcement learning can learn from any delayed reward. But in solving real world tasks, we still need to spend a lot of effort to adjust algorithms to fit task unique features. This paper proposes that the reason of this phenomenon is the sparse feedback feature of the nature, and a single algorithm, no matter how we improve it, can only solve dense feedback tasks or specific sparse feedback tasks. This paper first analyses how sparse feedback affects algorithm perfomance, and then proposes a pattern that explains how to accumulate knowledge to solve sparse feedback problems.