 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyphrase Extraction from Disaster-related Tweets
Paper and Code
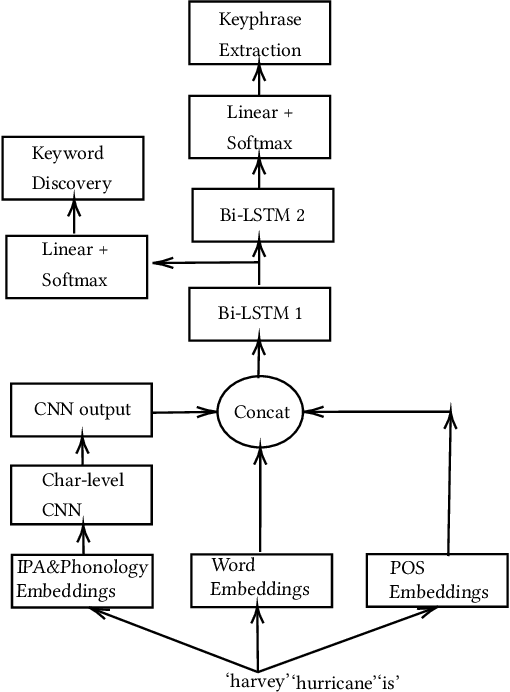
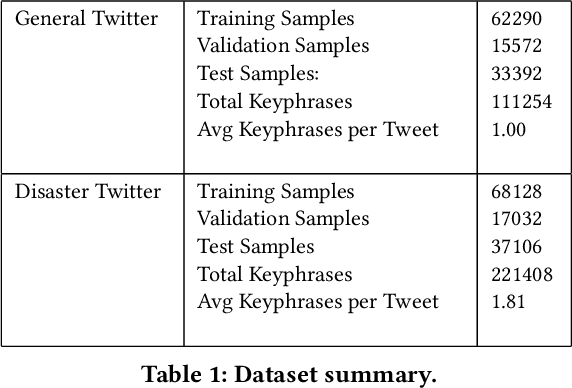
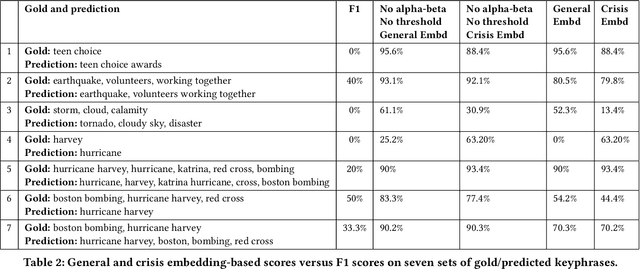
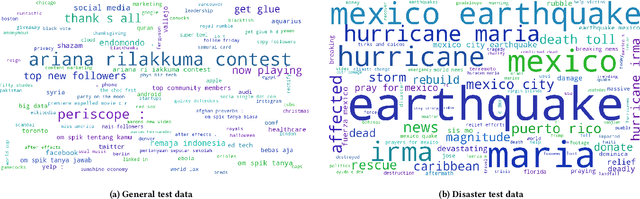
While keyphrase extraction has received considerable attention in recent years, relatively few studies exist on extracting keyphrases from social media platforms such as Twitter, and even fewer for extracting disaster-related keyphrases from such sources. During a disaster, keyphrases can be extremely useful for filtering relevant tweets that can enhance situational awareness. Previously, joint training of two different layers of a stacked Recurrent Neural Network for keyword discovery and keyphrase extraction had been shown to be effective in extracting keyphrases from general Twitter data. We improve the model's performance on both general Twitter data and disaster-related Twitter data by incorporating contextual word embeddings, POS-tags, phonetics, and phonological features. Moreover, we discuss the shortcomings of the often used F1-measure for evaluating the quality of predicted keyphrases with respect to the ground truth annotations. Instead of the F1-measure, we propose the use of embedding-based metrics to better capture the correctness of the predicted keyphrases. In addition, we also present a novel extension of an embedding-based metric. The extension allows one to better control the penalty for the difference in the number of ground-truth and predicted keyphrases