 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernels on Sample Sets via Nonparametric Divergence Estimates
Paper and Code
Dec 05, 2012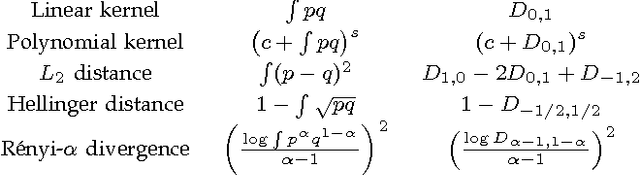
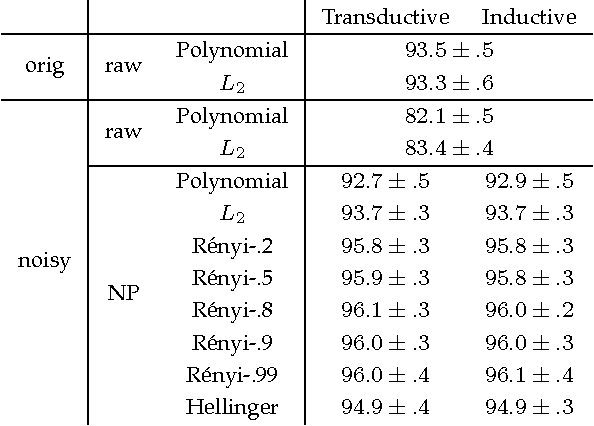
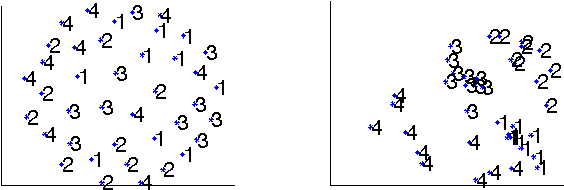
Most machine learning algorithms, such as classification or regression, treat the individual data point as the object of interest. Here we consider extending machine learning algorithms to operate on groups of data points. We suggest treating a group of data points as an i.i.d. sample set from an underlying feature distribution for that group. Our approach employs kernel machines with a kernel on i.i.d. sample sets of vectors. We define certain kernel functions on pairs of distributions, and then use a nonparametric estimator to consistently estimate those functions based on sample sets. The projection of the estimated Gram matrix to the cone of symmetric positive semi-definite matrices enables us to use kernel machines for classification, regression, anomaly detection, and low-dimensional embedding in the space of distributions. We present several numerical experiments both on real and simulated datasets to demonstrate the advantages of our new approach.