 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeeping it Simple: Language Models can learn Complex Molecular Distributions
Paper and Code
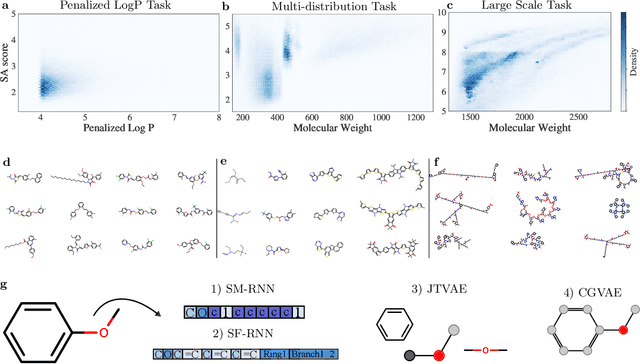
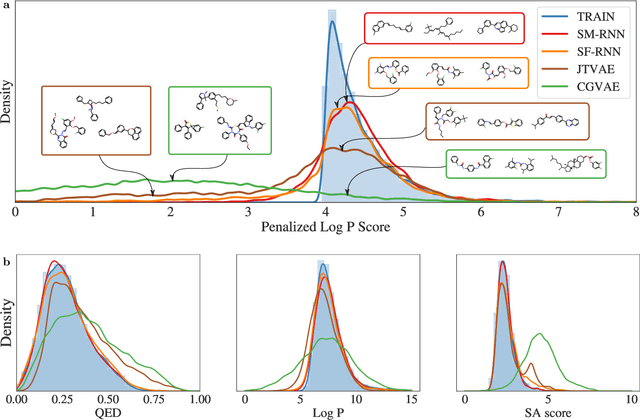
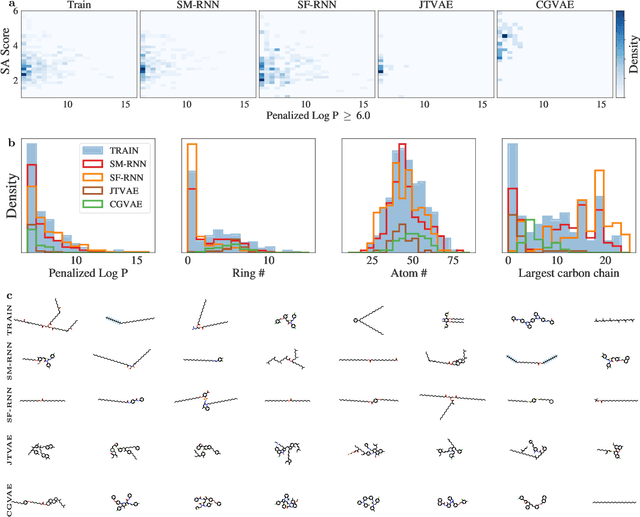
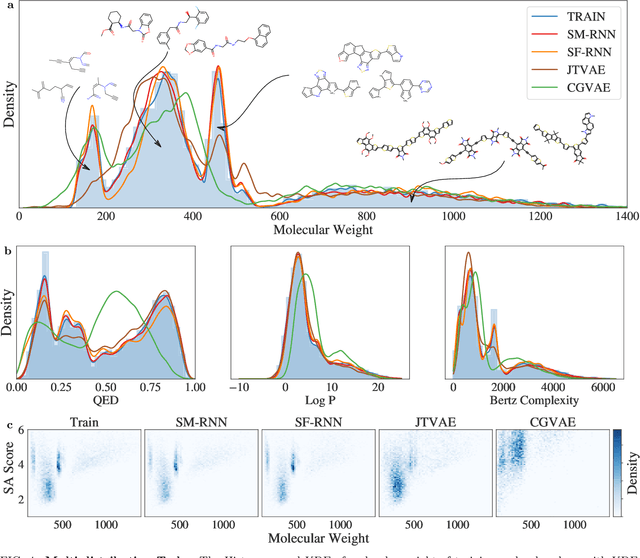
Deep generative models of molecules have grown immensely in popularity, trained on relevant datasets, these models are used to search through chemical space. The downstream utility of generative models for the inverse design of novel functional compounds depends on their ability to learn a training distribution of molecules. The most simple example is a language model that takes the form of a recurrent neural network and generates molecules using a string representation. More sophisticated are graph generative models, which sequentially construct molecular graphs and typically achieve state of the art results. However, recent work has shown that language models are more capable than once thought, particularly in the low data regime. In this work, we investigate the capacity of simple language models to learn distributions of molecules. For this purpose, we introduce several challenging generative modeling tasks by compiling especially complex distributions of molecules. On each task, we evaluate the ability of language models as compared with two widely used graph generative models. The results demonstrate that language models are powerful generative models, capable of adeptly learning complex molecular distributions -- and yield better performance than the graph models. Language models can accurately generate: distributions of the highest scoring penalized LogP molecules in ZINC15, multi-modal molecular distributions as well as the largest molecules in PubChem.