 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-Wav2vec 2.0: Automatic Speech Recognition based on Joint Decoding of Graphemes and Syllables
Paper and Code
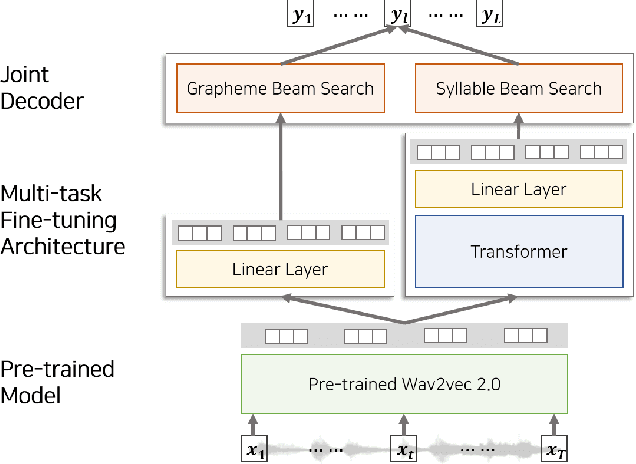
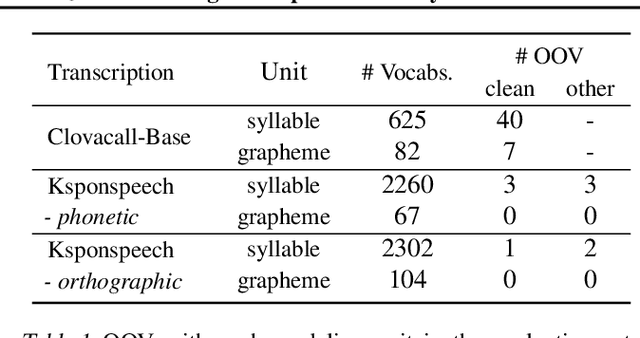
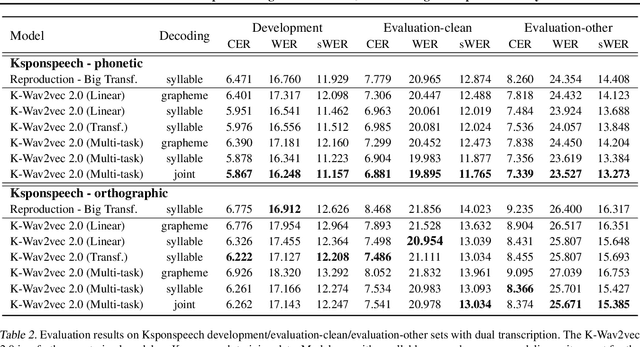
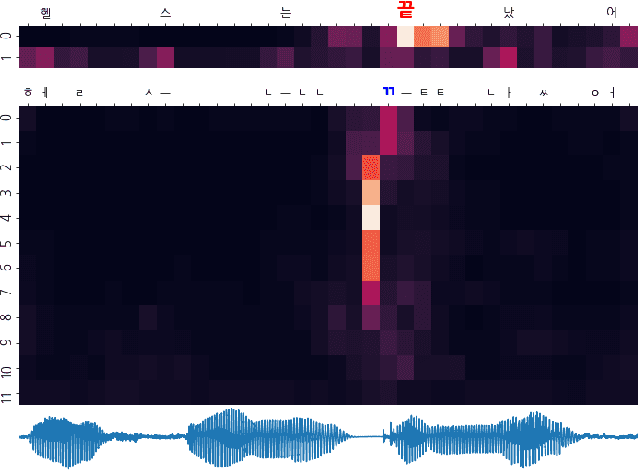
Wav2vec 2.0 is an end-to-end framework of self-supervised learning for speech representation that is successful in automatic speech recognition (ASR), but most of the work on the topic has been developed with a single language: English. Therefore, it is unclear whether the self-supervised framework is effective in recognizing other languages with different writing systems, such as Korean which uses the Hangul having a unique writing system. In this paper, we present K-Wav2Vec 2.0, which is a modified version of Wav2vec 2.0 designed for Korean automatic speech recognition by exploring and optimizing various factors of the original Wav2vec 2.0. In fine-tuning, we propose a multi-task hierarchical architecture to reflect the Korean writing structure. Moreover, a joint decoder is applied to alleviate the problem of words existing outside of the vocabulary. In pre-training, we attempted the cross-lingual transfer of the pre-trained model by further pre-training the English Wav2vec 2.0 on a Korean dataset, considering limited resources. Our experimental results demonstrate that the proposed method yields the best performance on both Korean ASR datasets: Ksponspeech (a large-scale Korean speech corpus) and Clovacall (a call-based dialog corpus). Further pre-training is also effective in language adaptation, leading to large improvements without additional data.