 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-VIL: Keypoints-based Visual Imitation Learning
Paper and Code
Sep 07, 2022
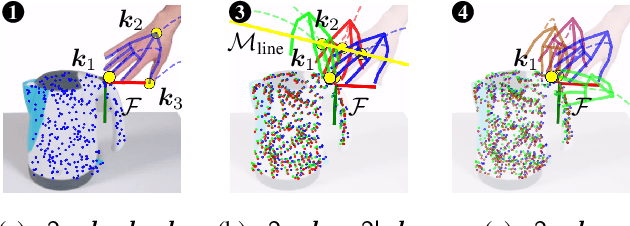
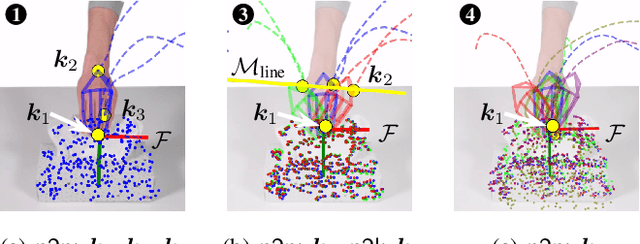
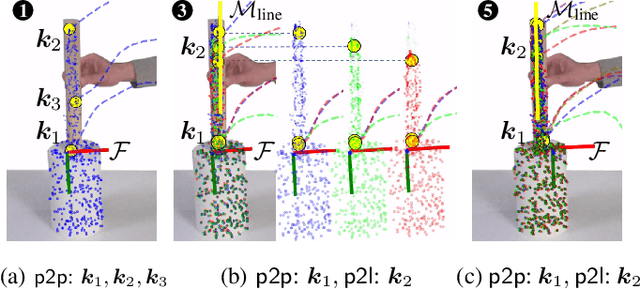
Visual imitation learning provides efficient and intuitive solutions for robotic systems to acquire novel manipulation skills. However, simultaneously learning geometric task constraints and control policies from visual inputs alone remains a challenging problem. In this paper, we propose an approach for keypoint-based visual imitation (K-VIL) that automatically extracts sparse, object-centric, and embodiment-independent task representations from a small number of human demonstration videos. The task representation is composed of keypoint-based geometric constraints on principal manifolds, their associated local frames, and the movement primitives that are then needed for the task execution. Our approach is capable of extracting such task representations from a single demonstration video, and of incrementally updating them when new demonstrations become available. To reproduce manipulation skills using the learned set of prioritized geometric constraints in novel scenes, we introduce a novel keypoint-based admittance controller. We evaluate our approach in several real-world applications, showcasing its ability to deal with cluttered scenes, new instances of categorical objects, and large object pose and shape variations, as well as its efficiency and robustness in both one-shot and few-shot imitation learning settings. Videos and source code are available at https://sites.google.com/view/k-vil.