 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJTubeSpeech: corpus of Japanese speech collected from YouTube for speech recognition and speaker verification
Paper and Code
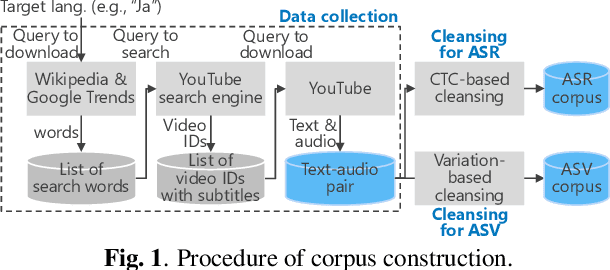

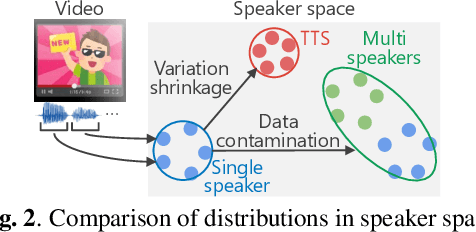
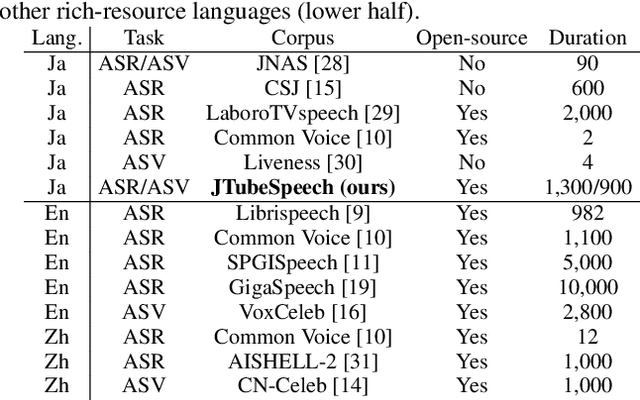
In this paper, we construct a new Japanese speech corpus called "JTubeSpeech." Although recent end-to-end learning requires large-size speech corpora, open-sourced such corpora for languages other than English have not yet been established. In this paper, we describe the construction of a corpus from YouTube videos and subtitles for speech recognition and speaker verification. Our method can automatically filter the videos and subtitles with almost no language-dependent processes. We consistently employ Connectionist Temporal Classification (CTC)-based techniques for automatic speech recognition (ASR) and a speaker variation-based method for automatic speaker verification (ASV). We build 1) a large-scale Japanese ASR benchmark with more than 1,300 hours of data and 2) 900 hours of data for Japanese ASV.