Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Learning Truth-Conditional Denotations and Groundings using Parallel Attention
Paper and Code
Apr 14, 2021


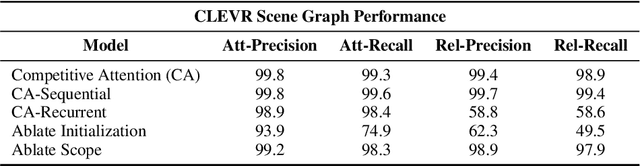
We present a model that jointly learns the denotations of words together with their groundings using a truth-conditional semantics. Our model builds on the neurosymbolic approach of Mao et al. (2019), learning to ground objects in the CLEVR dataset (Johnson et al., 2017) using a novel parallel attention mechanism. The model achieves state of the art performance on visual question answering, learning to detect and ground objects with question performance as the only training signal. We also show that the model is able to learn flexible non-canonical groundings just by adjusting answers to questions in the training set.
View paper on