 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Visual-Temporal Embedding for Unsupervised Learning of Actions in Untrimmed Sequences
Paper and Code
Feb 06, 2020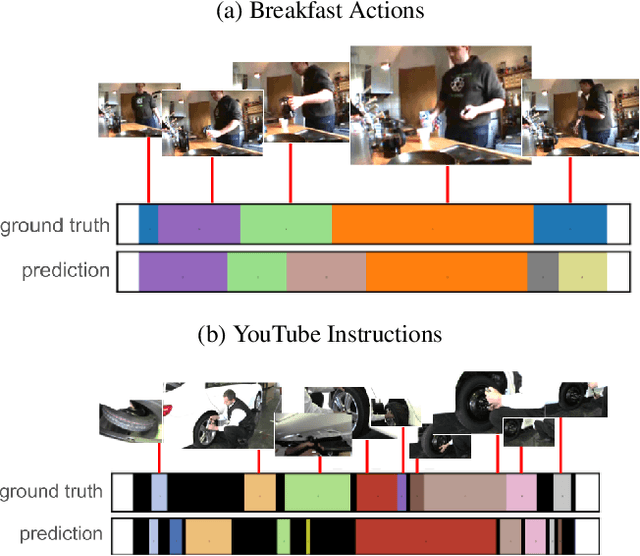



Understanding the structure of complex activities in videos is one of the many challenges faced by action recognition methods. To overcome this challenge, not only do methods need a solid knowledge of the visual structure of underlying features but also a good interpretation of how they could change over time. Consequently, action segmentation tasks must take into account not only the visual cues from individual frames, but their characteristics as a temporal sequence of features. This work presents our findings on the impact of incorporating both visual and temporal learning on an unsupervised action segmentation pipeline. We introduce a novel approach to extract relevant visual and temporal features from untrimmed sequences for the temporal localization of sub-activities within complex actions without any labeling information. Through extensive experimentation on two benchmark datasets -- Breakfast Actions, and YouTube Instructions -- we show that the proposed approach is able to provide a meaningful visual and temporal embedding from the visual cues from contiguous video frames and that it indeed helps in temporal segmentation.