 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Learning of Semantic Alignment and Object Landmark Detection
Paper and Code
Oct 02, 2019

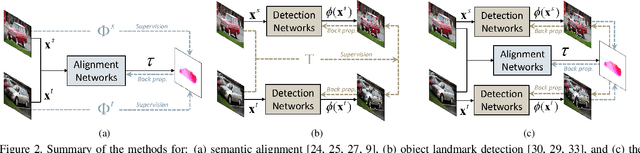

Convolutional neural networks (CNNs) based approaches for semantic alignment and object landmark detection have improved their performance significantly. Current efforts for the two tasks focus on addressing the lack of massive training data through weakly- or unsupervised learning frameworks. In this paper, we present a joint learning approach for obtaining dense correspondences and discovering object landmarks from semantically similar images. Based on the key insight that the two tasks can mutually provide supervisions to each other, our networks accomplish this through a joint loss function that alternatively imposes a consistency constraint between the two tasks, thereby boosting the performance and addressing the lack of training data in a principled manner. To the best of our knowledge, this is the first attempt to address the lack of training data for the two tasks through the joint learning. To further improve the robustness of our framework, we introduce a probabilistic learning formulation that allows only reliable matches to be used in the joint learning process. With the proposed method, state-of-the-art performance is attained on several standard benchmarks for semantic matching and landmark detection, including a newly introduced dataset, JLAD, which contains larger number of challenging image pairs than existing datasets.