 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint A-SNN: Joint Training of Artificial and Spiking Neural Networks via Self-Distillation and Weight Factorization
Paper and Code
May 03, 2023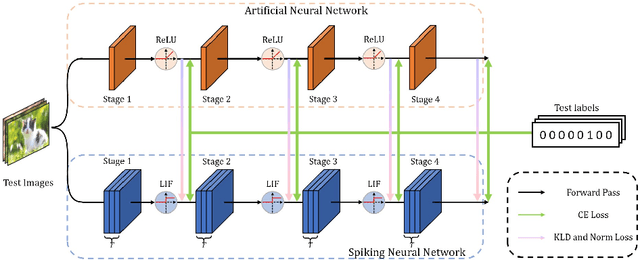
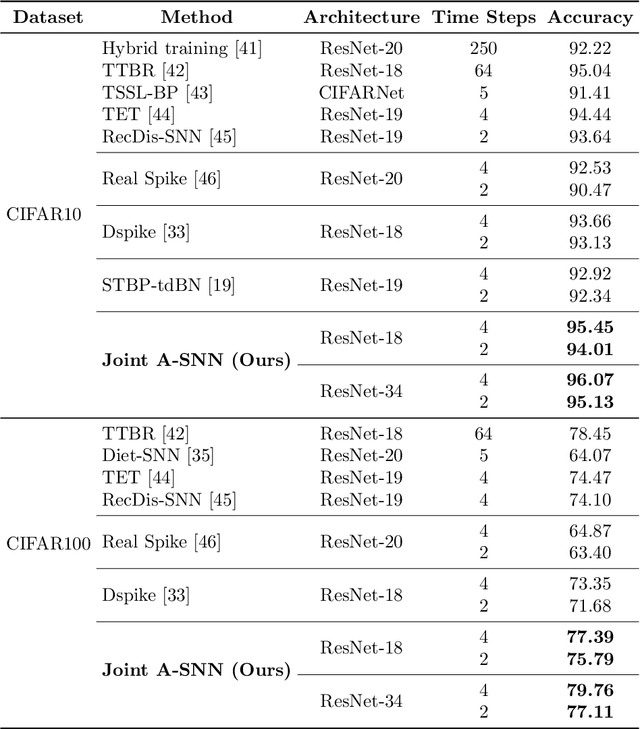
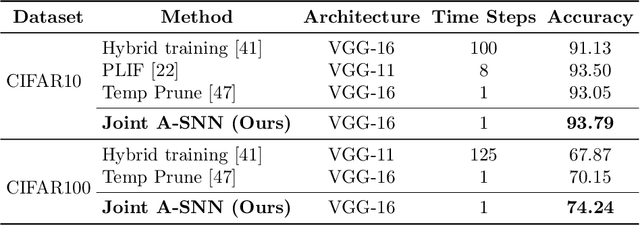
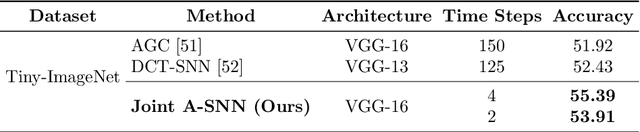
Emerged as a biology-inspired method, Spiking Neural Networks (SNNs) mimic the spiking nature of brain neurons and have received lots of research attention. SNNs deal with binary spikes as their activation and therefore derive extreme energy efficiency on hardware. However, it also leads to an intrinsic obstacle that training SNNs from scratch requires a re-definition of the firing function for computing gradient. Artificial Neural Networks (ANNs), however, are fully differentiable to be trained with gradient descent. In this paper, we propose a joint training framework of ANN and SNN, in which the ANN can guide the SNN's optimization. This joint framework contains two parts: First, the knowledge inside ANN is distilled to SNN by using multiple branches from the networks. Second, we restrict the parameters of ANN and SNN, where they share partial parameters and learn different singular weights. Extensive experiments over several widely used network structures show that our method consistently outperforms many other state-of-the-art training methods. For example, on the CIFAR100 classification task, the spiking ResNet-18 model trained by our method can reach to 77.39% top-1 accuracy with only 4 time steps.