Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs This a Joke? Detecting Humor in Spanish Tweets
Paper and Code
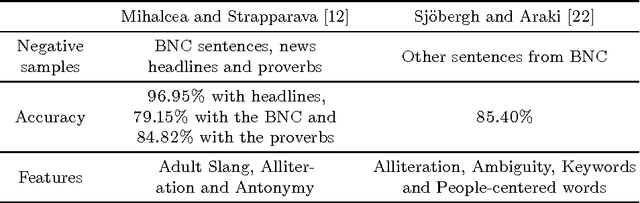


While humor has been historically studied from a psychological, cognitive and linguistic standpoint, its study from a computational perspective is an area yet to be explored in Computational Linguistics. There exist some previous works, but a characterization of humor that allows its automatic recognition and generation is far from being specified. In this work we build a crowdsourced corpus of labeled tweets, annotated according to its humor value, letting the annotators subjectively decide which are humorous. A humor classifier for Spanish tweets is assembled based on supervised learning, reaching a precision of 84% and a recall of 69%.
* Presented in Iberamia 2016. The final publication is available at
link.springer.com:
https://link.springer.com/chapter/10.1007%2F978-3-319-47955-2_12 * Preprint version, without referral
View paper on