 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs SGD a Bayesian sampler? Well, almost
Paper and Code
Jun 26, 2020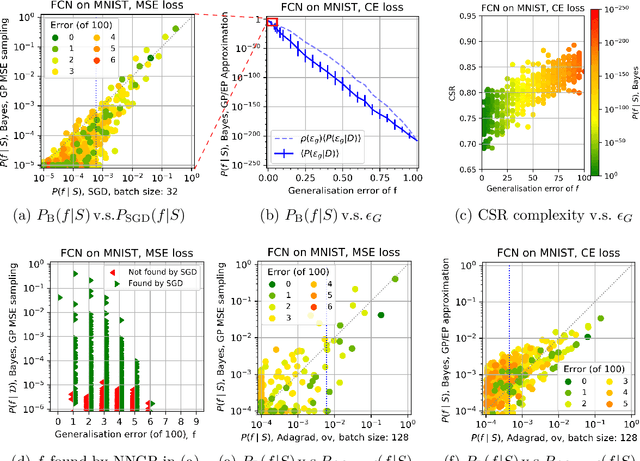


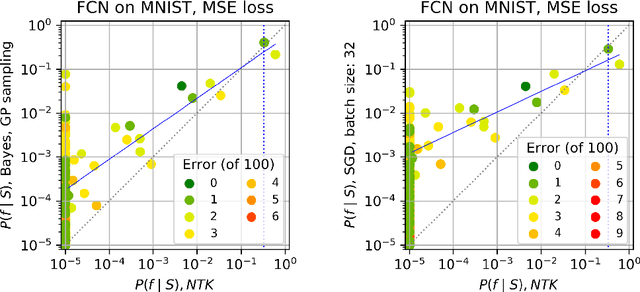
Overparameterised deep neural networks (DNNs) are highly expressive and so can, in principle, generate almost any function that fits a training dataset with zero error. The vast majority of these functions will perform poorly on unseen data, and yet in practice DNNs often generalise remarkably well. This success suggests that a trained DNN must have a strong inductive bias towards functions with low generalisation error. Here we empirically investigate this inductive bias by calculating, for a range of architectures and datasets, the probability $P_{SGD}(f\mid S)$ that an overparameterised DNN, trained with stochastic gradient descent (SGD) or one of its variants, converges on a function $f$ consistent with a training set $S$. We also use Gaussian processes to estimate the Bayesian posterior probability $P_B(f\mid S)$ that the DNN expresses $f$ upon random sampling of its parameters, conditioned on $S$. Our main findings are that $P_{SGD}(f\mid S)$ correlates remarkably well with $P_B(f\mid S)$ and that $P_B(f\mid S)$ is strongly biased towards low-error and low complexity functions. These results imply that strong inductive bias in the parameter-function map (which determines $P_B(f\mid S)$), rather than a special property of SGD, is the primary explanation for why DNNs generalise so well in the overparameterised regime. While our results suggest that the Bayesian posterior $P_B(f\mid S)$ is the first order determinant of $P_{SGD}(f\mid S)$, there remain second order differences that are sensitive to hyperparameter tuning. A function probability picture, based on $P_{SGD}(f\mid S)$ and/or $P_B(f\mid S)$, can shed new light on the way that variations in architecture or hyperparameter settings such as batch size, learning rate, and optimiser choice, affect DNN performance.