 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs deeper better? It depends on locality of relevant features
Paper and Code
May 26, 2020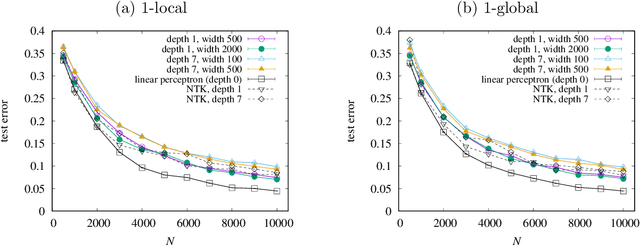
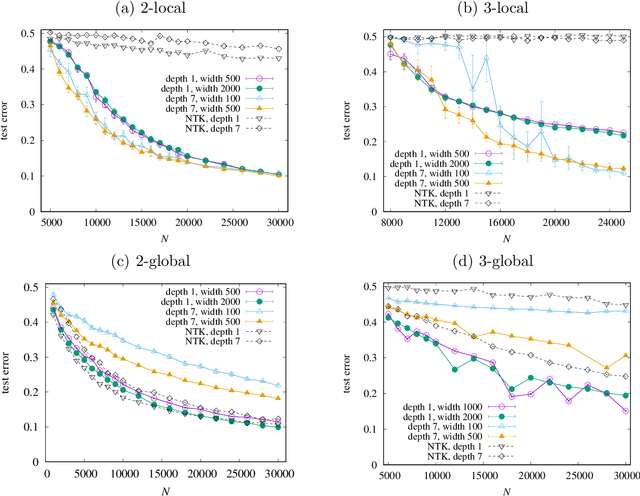
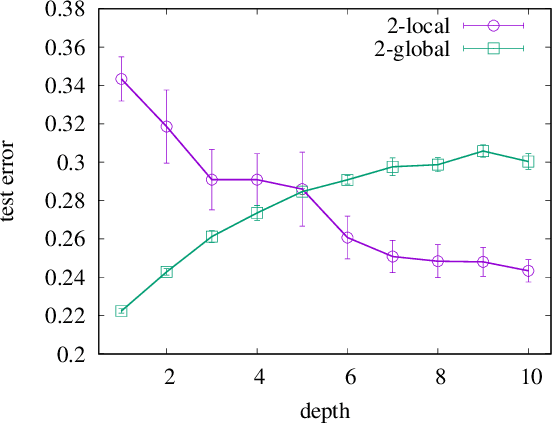
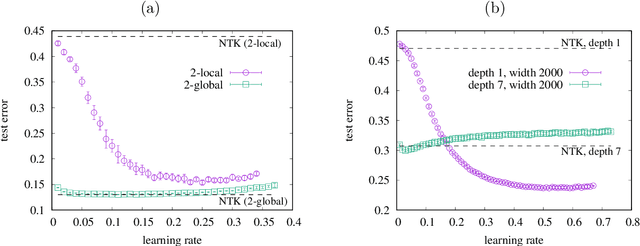
It has been recognized that a heavily overparameterized artificial neural network exhibits surprisingly good generalization performance in various machine-learning tasks. Recent theoretical studies have made attempts to unveil the mystery of the overparameterization. In most of those previous works, the overparameterization is achieved by increasing the width of the network, while the effect of increasing the depth has been less well understood. In this work, we investigate the effect of increasing the depth within an overparameterized regime. To gain an insight into the advantage of depth, we introduce local and global labels as abstract but simple classification rules. It turns out that the locality of the relevant feature for a given classification rule plays an important role; our experimental results suggest that deeper is better for local labels, whereas shallower is better for global labels. We also compare the results of finite networks with those of the neural tangent kernel (NTK), which is equivalent to an infinitely wide network with a proper initialization and an infinitesimal learning rate. It is shown that the NTK does not correctly capture the depth dependence of the generalization performance, which indicates the importance of the feature learning, rather than the lazy learning.