Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Failure Modes of the AUC metric and Exploring Alternatives for Evaluating Systems in Safety Critical Applications
Paper and Code
Oct 10, 2022
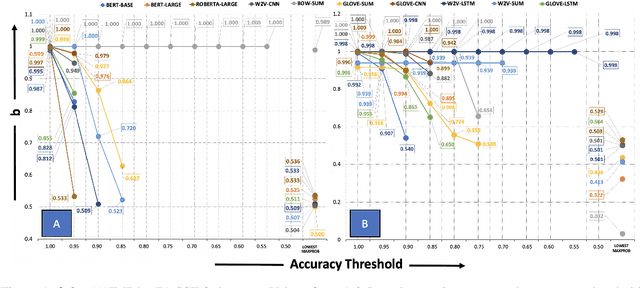
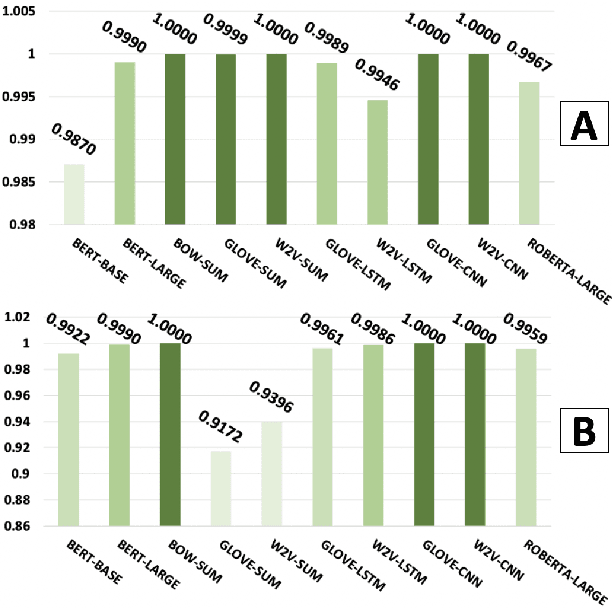

With the increasing importance of safety requirements associated with the use of black box models, evaluation of selective answering capability of models has been critical. Area under the curve (AUC) is used as a metric for this purpose. We find limitations in AUC; e.g., a model having higher AUC is not always better in performing selective answering. We propose three alternate metrics that fix the identified limitations. On experimenting with ten models, our results using the new metrics show that newer and larger pre-trained models do not necessarily show better performance in selective answering. We hope our insights will help develop better models tailored for safety-critical applications.
View paper on