 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Content-Aware Neural Text-To-Speech MOS Prediction Using Prosodic and Linguistic Features
Paper and Code
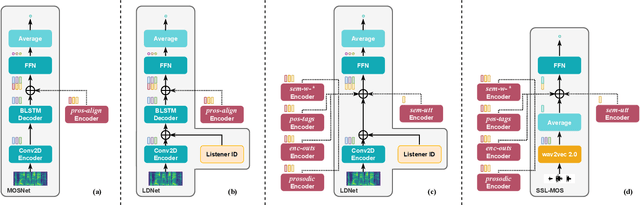
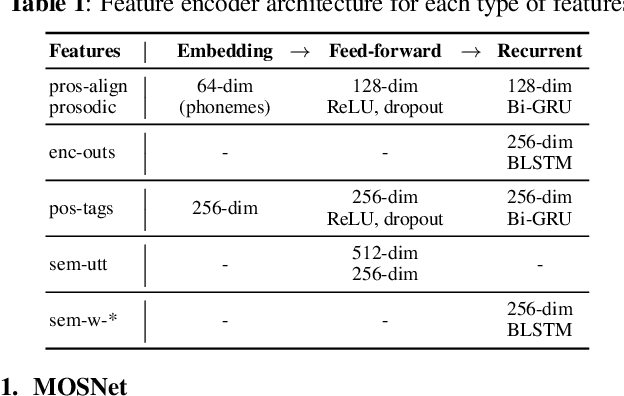
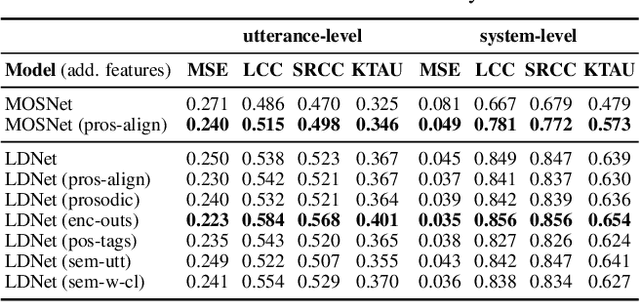
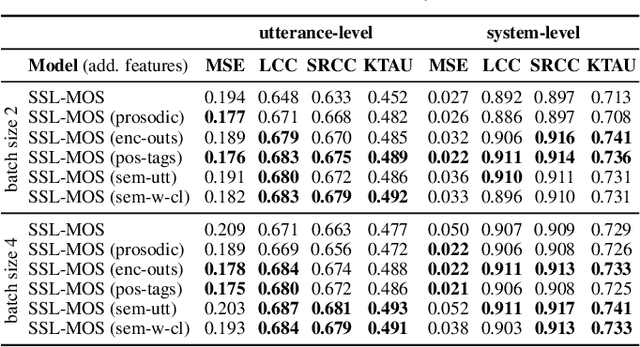
Current state-of-the-art methods for automatic synthetic speech evaluation are based on MOS prediction neural models. Such MOS prediction models include MOSNet and LDNet that use spectral features as input, and SSL-MOS that relies on a pretrained self-supervised learning model that directly uses the speech signal as input. In modern high-quality neural TTS systems, prosodic appropriateness with regard to the spoken content is a decisive factor for speech naturalness. For this reason, we propose to include prosodic and linguistic features as additional inputs in MOS prediction systems, and evaluate their impact on the prediction outcome. We consider phoneme level F0 and duration features as prosodic inputs, as well as Tacotron encoder outputs, POS tags and BERT embeddings as higher-level linguistic inputs. All MOS prediction systems are trained on SOMOS, a neural TTS-only dataset with crowdsourced naturalness MOS evaluations. Results show that the proposed additional features are beneficial in the MOS prediction task, by improving the predicted MOS scores' correlation with the ground truths, both at utterance-level and system-level predictions.