 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Alternatives to the Root Mean Square for Adaptive Gradient Methods
Paper and Code
Jun 10, 2021

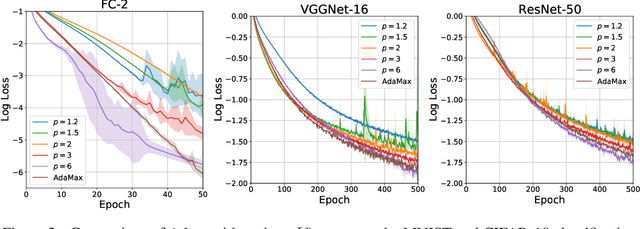
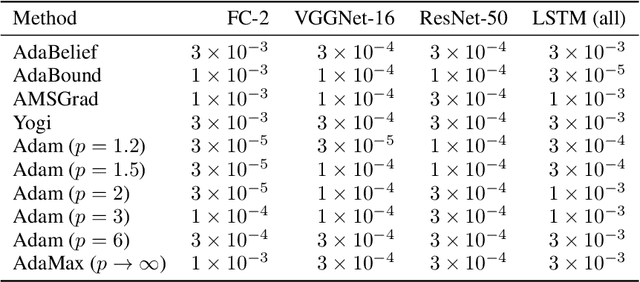
Adam is an adaptive gradient method that has experienced widespread adoption due to its fast and reliable training performance. Recent approaches have not offered significant improvement over Adam, often because they do not innovate upon one of its core features: normalization by the root mean square (RMS) of recent gradients. However, as noted by Kingma and Ba (2015), any number of $L^p$ normalizations are possible, with the RMS corresponding to the specific case of $p=2$. In our work, we theoretically and empirically characterize the influence of different $L^p$ norms on adaptive gradient methods for the first time. We show mathematically how the choice of $p$ influences the size of the steps taken, while leaving other desirable properties unaffected. We evaluate Adam with various $L^p$ norms on a suite of deep learning benchmarks, and find that $p > 2$ consistently leads to improved learning speed and final performance. The choices of $p=3$ or $p=6$ also match or outperform state-of-the-art methods in all of our experiments.