 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverted Pyramid Multi-task Transformer for Dense Scene Understanding
Paper and Code
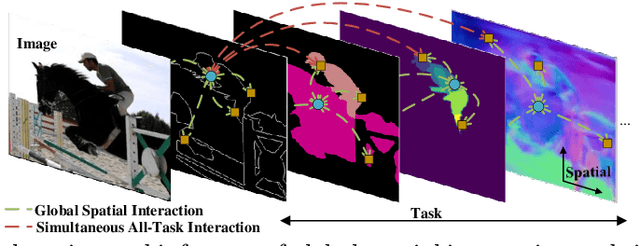
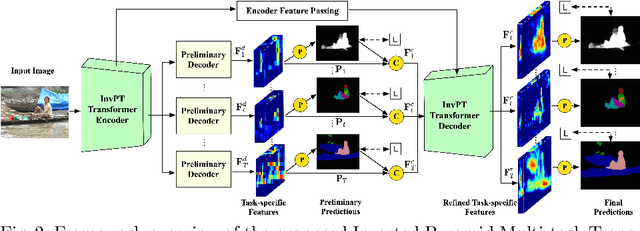

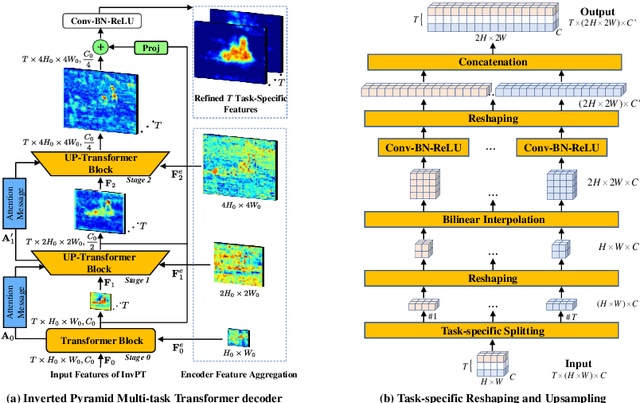
Multi-task dense scene understanding is a thriving research domain that requires simultaneous perception and reasoning on a series of correlated tasks with pixel-wise prediction. Most existing works encounter a severe limitation of modeling in the locality due to heavy utilization of convolution operations, while learning interactions and inference in a global spatial-position and multi-task context is critical for this problem. In this paper, we propose a novel end-to-end Inverted Pyramid multi-task (InvPT) Transformer to perform simultaneous modeling of spatial positions and multiple tasks in a unified framework. To the best of our knowledge, this is the first work that explores designing a transformer structure for multi-task dense prediction for scene understanding. Besides, it is widely demonstrated that a higher spatial resolution is remarkably beneficial for dense predictions, while it is very challenging for existing transformers to go deeper with higher resolutions due to huge complexity to large spatial size. InvPT presents an efficient UP-Transformer block to learn multi-task feature interaction at gradually increased resolutions, which also incorporates effective self-attention message passing and multi-scale feature aggregation to produce task-specific prediction at a high resolution. Our method achieves superior multi-task performance on NYUD-v2 and PASCAL-Context datasets respectively, and significantly outperforms previous state-of-the-arts. Code and trained models will be publicly available.