 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntriguing Properties of Robust Classification
Paper and Code
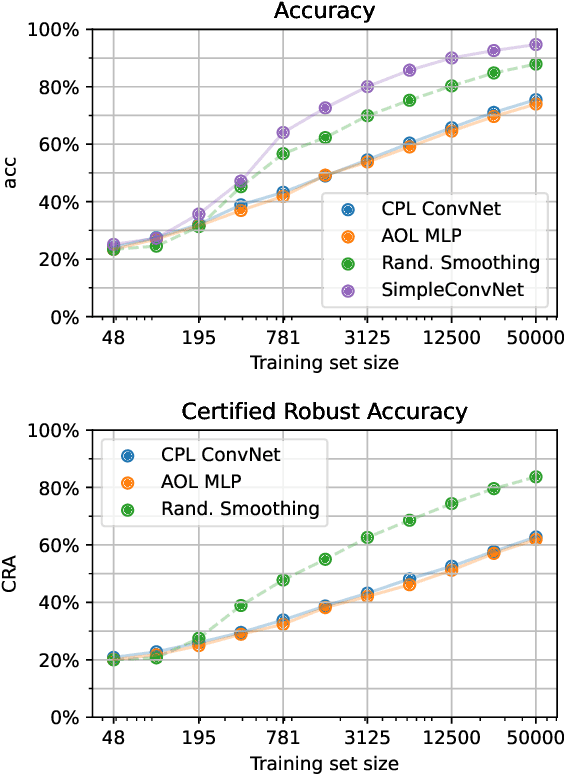
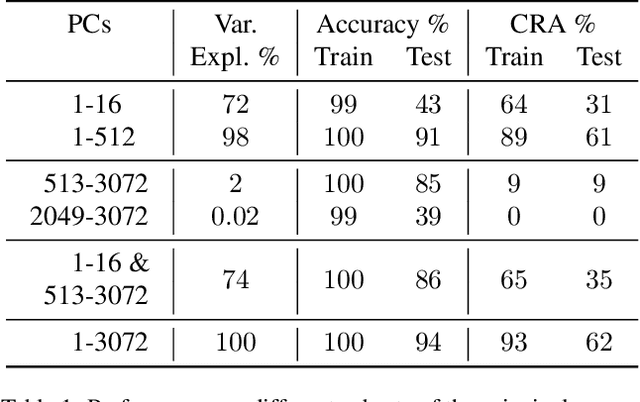
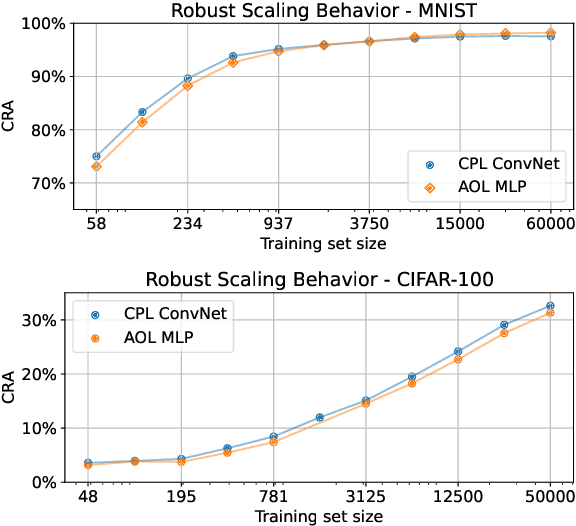
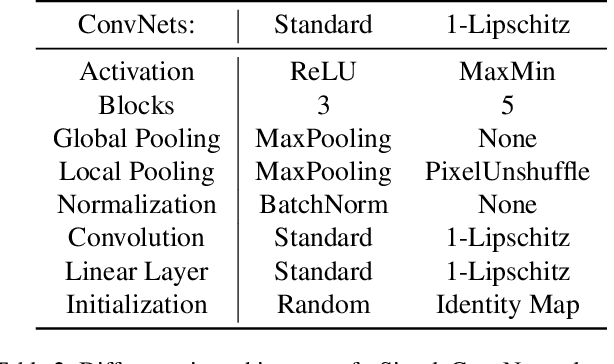
Despite extensive research since the community learned about adversarial examples 10 years ago, we still do not know how to train high-accuracy classifiers that are guaranteed to be robust to small perturbations of their inputs. Previous works often argued that this might be because no classifier exists that is robust and accurate at the same time. However, in computer vision this assumption does not match reality where humans are usually accurate and robust on most tasks of interest. We offer an alternative explanation and show that in certain settings robust generalization is only possible with unrealistically large amounts of data. More precisely we find a setting where a robust classifier exists, it is easy to learn an accurate classifier, yet it requires an exponential amount of data to learn a robust classifier. Based on this theoretical result, we explore how well robust classifiers generalize on datasets such as CIFAR-10. We come to the conclusion that on this datasets, the limitation of current robust models also lies in the generalization, and that they require a lot of data to do well on the test set. We also show that the problem is not in the expressiveness or generalization capabilities of current architectures, and that there are low magnitude features in the data which are useful for non-robust generalization but are not available for robust classifiers.