 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Black Box Models with Statistical Guarantees
Paper and Code

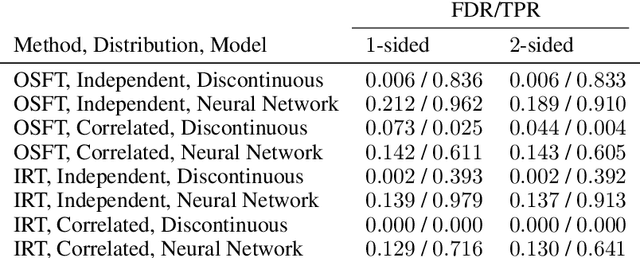
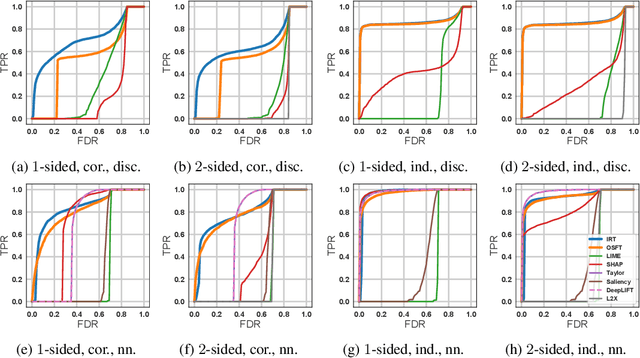

While many methods for interpreting machine learning models have been proposed, they are frequently ad hoc, difficult to evaluate, and come with no statistical guarantees on the error rate. This is especially problematic in scientific domains, where interpretations must be accurate and reliable. In this paper, we cast black box model interpretation as a hypothesis testing problem. The task is to discover "important" features by testing whether the model prediction is significantly different from what would be expected if the features were replaced with randomly-sampled counterfactuals. We derive a multiple hypothesis testing framework for finding important features that enables control over the false discovery rate. We propose two testing methods, as well as analogs of one-sided and two-sided tests. In simulation, the methods have high power and compare favorably against existing interpretability methods. When applied to vision and language models, the framework selects features that intuitively explain model predictions.