 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Temporal Class Activation Representation for Audio Spoofing Detection
Paper and Code
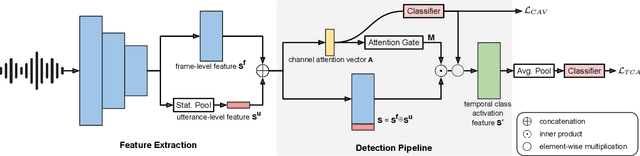
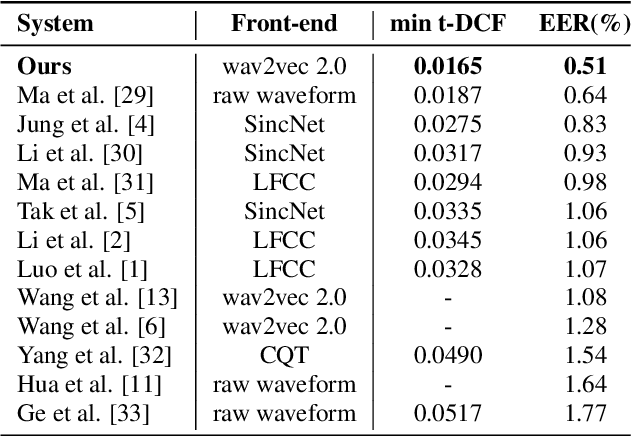
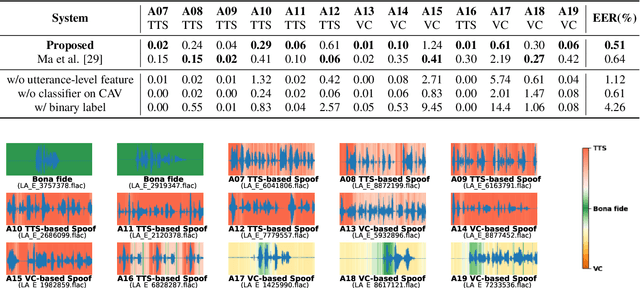
Explaining the decisions made by audio spoofing detection models is crucial for fostering trust in detection outcomes. However, current research on the interpretability of detection models is limited to applying XAI tools to post-trained models. In this paper, we utilize the wav2vec 2.0 model and attentive utterance-level features to integrate interpretability directly into the model's architecture, thereby enhancing transparency of the decision-making process. Specifically, we propose a class activation representation to localize the discriminative frames contributing to detection. Furthermore, we demonstrate that multi-label training based on spoofing types, rather than binary labels as bonafide and spoofed, enables the model to learn distinct characteristics of different attacks, significantly improving detection performance. Our model achieves state-of-the-art results, with an EER of 0.51% and a min t-DCF of 0.0165 on the ASVspoof2019-LA set.