 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretability at Scale: Identifying Causal Mechanisms in Alpaca
Paper and Code
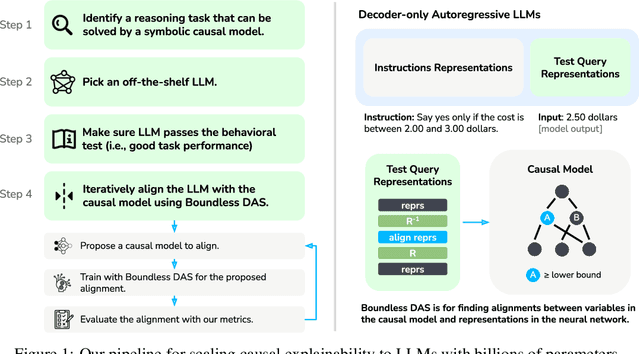
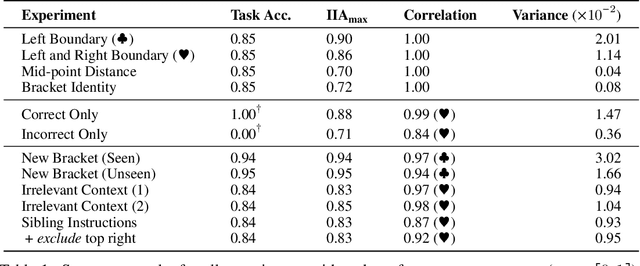
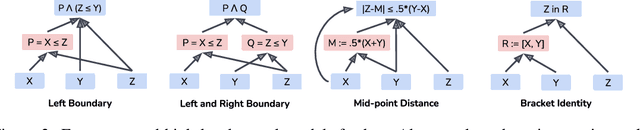
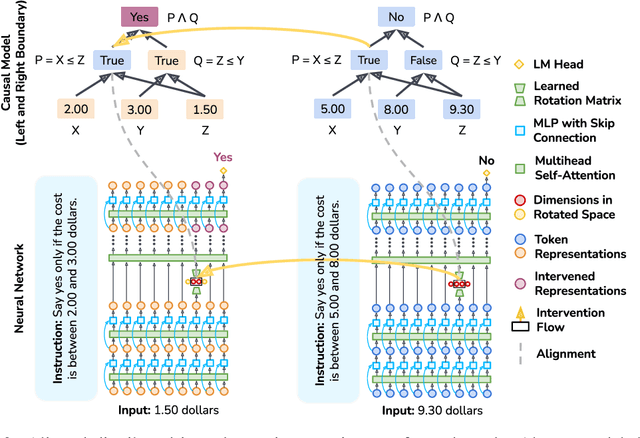
Obtaining human-interpretable explanations of large, general-purpose language models is an urgent goal for AI safety. However, it is just as important that our interpretability methods are faithful to the causal dynamics underlying model behavior and able to robustly generalize to unseen inputs. Distributed Alignment Search (DAS) is a powerful gradient descent method grounded in a theory of causal abstraction that uncovered perfect alignments between interpretable symbolic algorithms and small deep learning models fine-tuned for specific tasks. In the present paper, we scale DAS significantly by replacing the remaining brute-force search steps with learned parameters -- an approach we call DAS. This enables us to efficiently search for interpretable causal structure in large language models while they follow instructions. We apply DAS to the Alpaca model (7B parameters), which, off the shelf, solves a simple numerical reasoning problem. With DAS, we discover that Alpaca does this by implementing a causal model with two interpretable boolean variables. Furthermore, we find that the alignment of neural representations with these variables is robust to changes in inputs and instructions. These findings mark a first step toward deeply understanding the inner-workings of our largest and most widely deployed language models.