 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInter-channel Conv-TasNet for multichannel speech enhancement
Paper and Code
Nov 08, 2021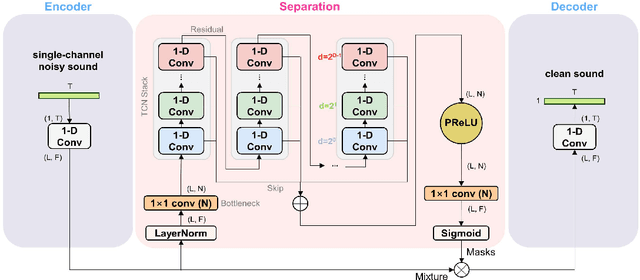

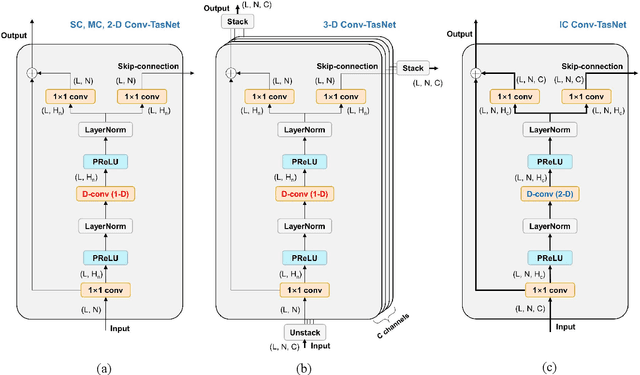
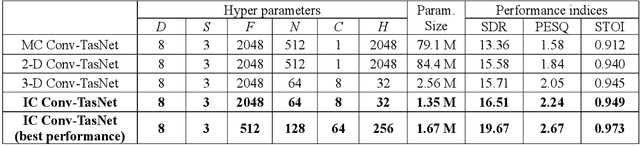
Speech enhancement in multichannel settings has been realized by utilizing the spatial information embedded in multiple microphone signals. Moreover, deep neural networks (DNNs) have been recently advanced in this field; however, studies on the efficient multichannel network structure fully exploiting spatial information and inter-channel relationships is still in its early stages. In this study, we propose an end-to-end time-domain speech enhancement network that can facilitate the use of inter-channel relationships at individual layers of a DNN. The proposed technique is based on a fully convolutional time-domain audio separation network (Conv-TasNet), originally developed for speech separation tasks. We extend Conv-TasNet into several forms that can handle multichannel input signals and learn inter-channel relationships. To this end, we modify the encoder-mask-decoder structures of the network to be compatible with 3-D tensors defined over spatial channels, features, and time dimensions. In particular, we conduct extensive parameter analyses on the convolution structure and propose independent assignment of the depthwise and 1$\times$1 convolution layers to the feature and spatial dimensions, respectively. We demonstrate that the enriched inter-channel information from the proposed network plays a significant role in suppressing noisy signals impinging from various directions. The proposed inter-channel Conv-TasNet outperforms the state-of-the-art multichannel variants of neural networks, even with one-tenth of their parameter size. The performance of the proposed model is evaluated using the CHiME-3 dataset, which exhibits a remarkable improvement in SDR, PESQ, and STOI.