 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntent-based Deep Reinforcement Learning for Multi-agent Informative Path Planning
Paper and Code
Mar 09, 2023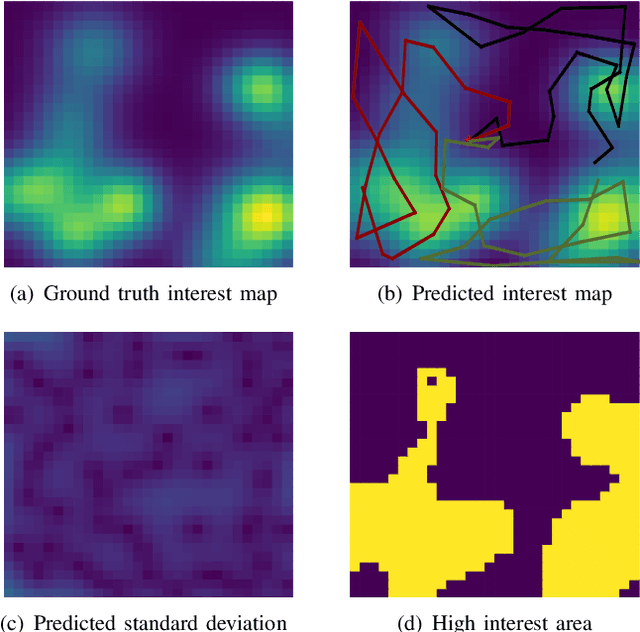
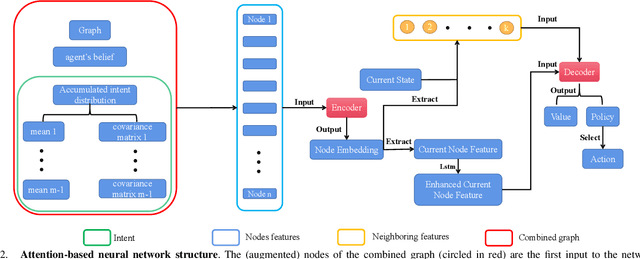
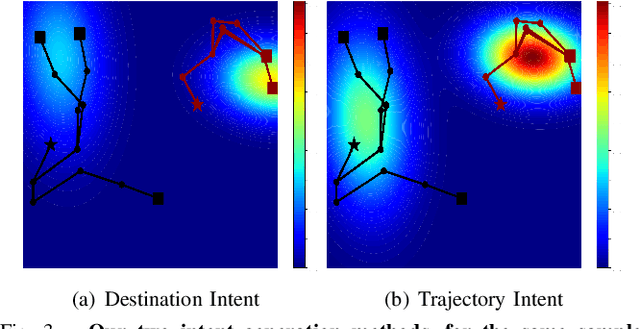
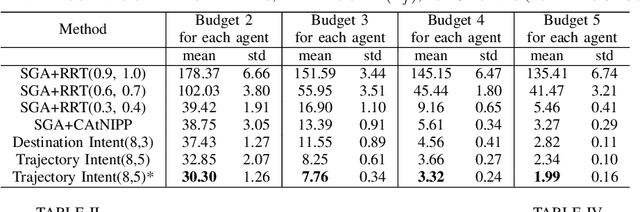
In multi-agent informative path planning (MAIPP), agents must collectively construct a global belief map of an underlying distribution of interest (e.g., gas concentration, light intensity, or pollution levels) over a given domain, based on measurements taken along their trajectory. They must frequently replan their path to balance the distributed exploration of new areas and the collective, meticulous exploitation of known high-interest areas, to maximize the information gained within a predefined budget (e.g., path length or working time). A common approach to achieving such cooperation relies on planning the agents' paths reactively, conditioned on other agents' future actions. However, as the agent's belief is updated continuously, these predicted future actions may not end up being the ones executed by agents, introducing a form of noise/inaccuracy in the system and often decreasing performance. In this work, we propose a decentralized deep reinforcement learning (DRL) approach to MAIPP, which relies on an attention-based neural network, where agents optimize long-term individual and cooperative objectives by explicitly sharing their intent (i.e., medium-/long-term future positions distribution, obtained from their individual policy) in a reactive, asynchronous manner. That is, in our work, intent sharing allows agents to learn to claim/avoid broader areas of the world. Moreover, since our approach relies on learned attention over these shared intents, agents are able to learn to recognize the useful portion(s) of these (imperfect) predictions to maximize cooperation even in the presence of imperfect information. Our comparison experiments demonstrate the performance of our approach compared to its variants and high-quality baselines over a large set of MAIPP simulations.